What is Context Engineering? The Truth About AI Success
The AI project stalled. Not because the model was wrong. Not because the prompts were weak. The model had all the capability we needed. The prompts were clear.
The problem was that the AI had no idea what we were actually building.
It did not know our naming conventions. It did not know which decisions we had already made. It did not know the constraints we had discovered through six weeks of testing. Every session started from zero. Every output needed extensive rework. And every person on the team blamed something different: the model, the tool, the workflow, the person writing the prompts.
None of them were wrong. But none of them were identifying the real problem.
The real problem was the information environment. The AI was operating without the context it needed to perform reliably. And nobody had a name for that problem yet.
That name is context engineering. The practitioner who solves it is a context engineer.
| A context engineer is a practitioner who designs the information systems and knowledge architectures that enable AI to perform reliably. They focus on what the AI knows, not how it is asked. |
This article explains what a context engineer does, how context engineering differs from prompt engineering, and why this discipline is becoming one of the most important skills in any organization deploying AI systems at scale.
What People Get Wrong About Why AI Fails
Most teams treat AI failures as prompt failures. The output was wrong, so the instruction must have been wrong. Write a better prompt. Add more detail. Be more specific.
That logic holds for simple, isolated queries. It breaks when you are building systems.
In production AI environments, the prompt is a tiny fraction of what the model actually sees. Conversation history, retrieved documents, organizational standards, tool outputs, session state, and dynamically assembled knowledge all flow into the context window. The prompt sits on top of all of it. If the foundation is unstable, the prompt does not save you.
I saw this pattern repeat across multiple projects before I understood it clearly. We would spend hours refining a prompt, get better output for one or two cycles, then watch performance degrade again. The problem was not the instruction layer. The problem was the information layer beneath it.
Andrej Karpathy on X, described this shift precisely in June 2025: context engineering is the delicate art and science of filling the context window with just the right information for the next step. Tobi Lutke, CEO of Shopify, put it even more directly: the core skill is providing all the context for the task to be plausibly solvable by the LLM.
Context engineering is not prompt engineering with extra steps. It is a different discipline with different failure modes, different architecture decisions, and a different professional skill set.
| Prompt engineering optimizes what you ask. Context engineering designs the information environment before the question is ever written. |
Why Context Matters More Than Prompts
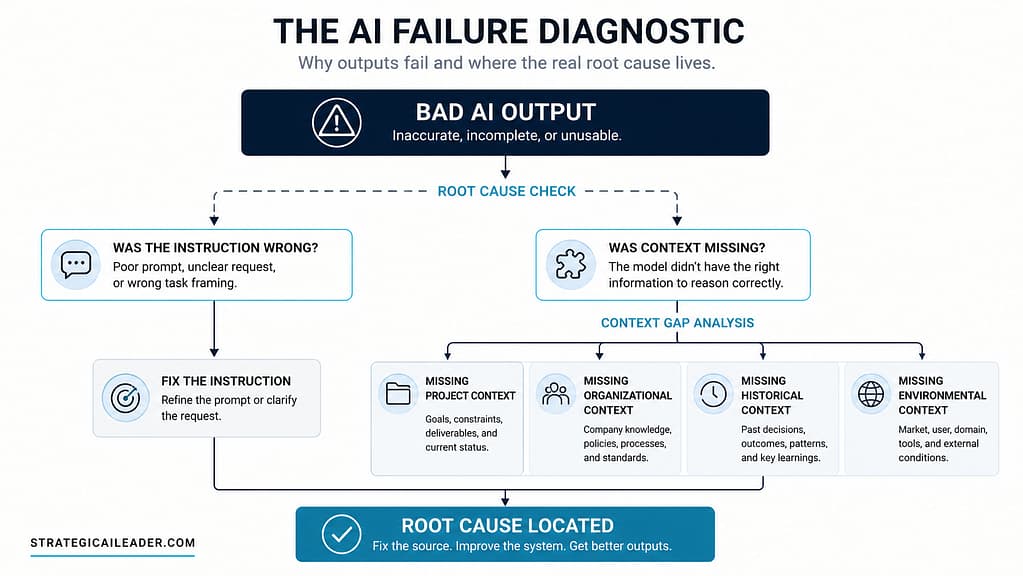
They are context failures that originate upstream in the information architecture.
Here is a concrete way to see the difference.
Two developers are building the same feature using an AI coding agent. Developer A writes careful, specific prompts and gets reasonable output about 60% of the time. Developer B writes average prompts but has structured their project context thoroughly: requirements documents, architecture decisions, naming conventions, and a record of prior decisions are all accessible to the agent before generation begins.
Developer B produces consistently better output. Not because they are better at prompting. Because the agent knows what it is building, what constraints apply, and what has already been decided.
This is the core insight of context engineering: the information architecture beneath the prompt determines the quality ceiling of the output. Better prompts push you toward that ceiling. Better context raises it.
The practical implication is significant. Teams that invest in prompt optimization while neglecting context infrastructure will hit a performance wall. Teams that build context systems first will compound their advantage over time because the same context investment improves performance across every future interaction, not just the current one.
I built our content production pipeline around this principle after realizing that inconsistent article quality had almost nothing to do with how we were prompting. It was about what information the model had access to when generation began. Once we structured project context, framework registries, and entity definitions into the workflow as blocking requirements, quality consistency improved significantly across every article produced.
| Why It Matters The leverage in AI systems has shifted decisively. As models have grown more capable and context windows have stretched to millions of tokens, clever prompt phrasing delivers diminishing returns. What moves the needle now is the quality of the information ecosystem surrounding the model, not the wording of the instruction. |
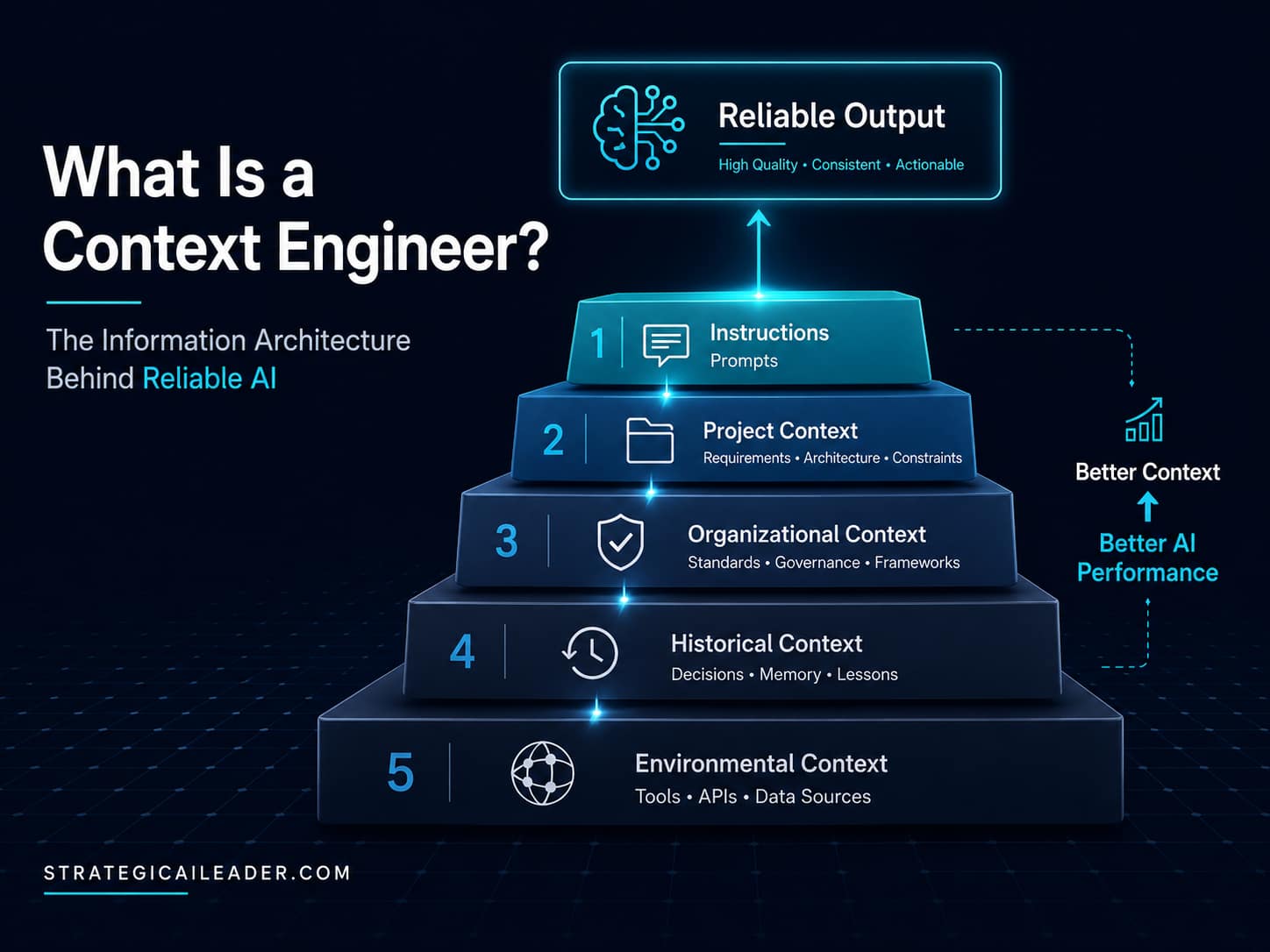
The Context Stack: A Five-Layer Information Architecture
Context engineering needs a framework. Without one, it becomes an abstract concept that practitioners struggle to implement systematically.
The framework I use is what I call my Context Stack. It organizes everything an AI agent needs to perform reliably into five distinct layers, each building on the one below it.
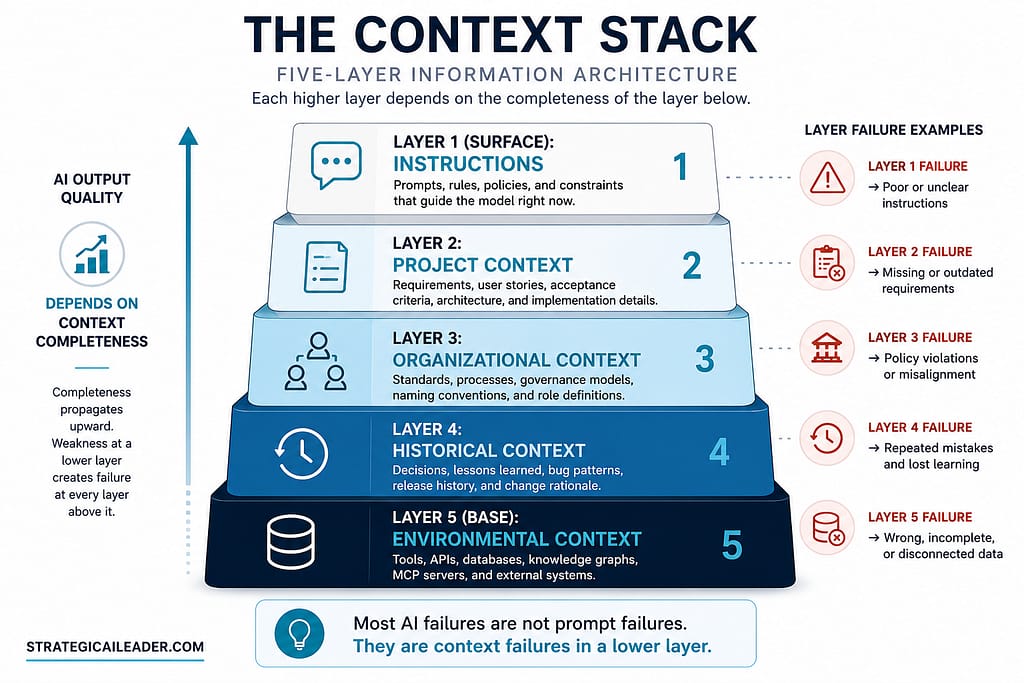
learn from history, and access the right context at the right time.
Layer 1: Instructions
This is the layer most people think of when they think about AI input. Prompts, system messages, rules, and policies all live here. It is the most visible layer and receives the most attention. It is also the layer that matters least when the layers below it are poorly populated.
Instructions tell the AI what to do. The other four layers tell it what it needs to know to do it well.
Layer 2: Project Context
Project context includes everything specific to what you are currently building. Requirements documents, user stories, acceptance criteria, architecture decisions, technical constraints, and scope definitions all belong here.
Without project context, the AI has to infer what you are building from conversational cues alone. It makes assumptions. Many of those assumptions are wrong, and the errors compound across sessions.
The first time I structured project context into a workflow as a blocking step, not an optional input, the improvement was immediate. Sessions that previously required three or four rounds of correction to get on track started producing usable output from the first generation. The instructions had not changed. The project context had.
Layer 3: Organizational Context
Organizational context is what makes AI output feel like it belongs to your organization rather than a generic system. Naming conventions, coding standards, editorial voice, governance frameworks, process documentation, and institutional policies all live here.
This layer is almost always missing in early AI implementations. Organizations get excited about what AI can do and skip the step of telling it who they are. The result is output that is technically competent but organizationally misaligned.
Building and maintaining organizational context is ongoing work. It is also a compounding asset. Every new AI system or workflow you add benefits from organizational context that already exists.
Layer 4: Historical Context
Historical context covers decisions already made, lessons learned from prior attempts, known failure patterns, resolved bugs, and the evolution of thinking over time.
This layer is what separates a system with memory from a system that starts fresh every session. AI agents without historical context repeat mistakes, ignore prior decisions, and force human operators to re-explain context that should already be available.
The Model Context Protocol (MCP) represents one architecture for making historical context accessible to agents at runtime. When I started building MCP connections into our workflows, the improvement in decision continuity across sessions was significant. The agent stopped asking questions we had already answered.
Layer 5: Environmental Context
Environmental context is the real-time information layer: which tools are available, what APIs are accessible, what databases exist, what the current system state is, and what external data sources can be queried.
This layer changes the most frequently and requires active maintenance. Stale environmental context produces confident but wrong outputs, because the agent believes it has access to capabilities or data that no longer apply.
Environmental context is where the discipline of context engineering intersects most directly with software architecture. Managing it well requires decisions about how tools are registered, how API schemas are kept current, and how agents validate what they can access before they begin executing.
What Context Engineers Actually Build
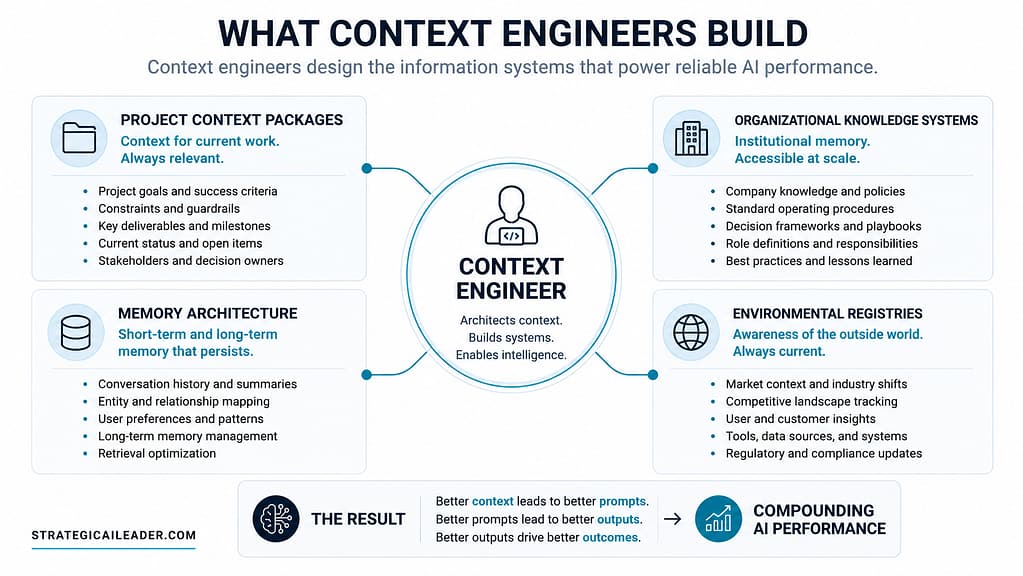
The role is emerging, but the work already exists. Most organizations just have nobody responsible for it.
Context engineers build and maintain the systems that populate the Context Stack. The specific outputs depend on the organization and the AI systems being deployed, but the categories are consistent.
Project Context Packages
A project context package is a structured document (or set of documents) that captures everything an AI agent needs to know about a specific project before generation begins. It includes scope, constraints, decisions made, naming conventions, open questions, and prior attempts.
This sounds like basic documentation. It is. But designed specifically for AI consumption, with structured fields rather than free-form narrative, and maintained as a living document throughout the project rather than written once and abandoned.
Organizational Knowledge Systems
Organizational context does not load itself into the context window. Context engineers design and maintain the systems that make it accessible: knowledge bases, framework registries, entity registries, terminology guides, and governance documents structured for AI retrieval rather than human browsing.
The distinction matters. Documents written for humans to read are often poorly suited for AI retrieval. Context engineers redesign them, or build parallel versions, optimized for what the AI needs to pull into the context window at the right moment.
Memory Architecture
Historical context requires architecture decisions: what to persist, how long to retain it, when to surface it, and how to prevent stale information from degrading output quality.
At MyEListing, we implemented a structured decision log that AI agents could query before beginning any analysis work. The goal was to prevent the model from recommending approaches we had already evaluated and rejected. Human review time for AI outputs dropped from 28 minutes per output to 9 minutes after we implemented this pattern, because the model was no longer producing suggestions that required manual filtering against institutional memory.
Environmental Registries
Context engineers maintain registries of available tools, APIs, databases, and data sources, along with their current state, schema, and access constraints. These registries are what agents consult before they begin executing to understand what capabilities are actually available.
Without these registries, agents hallucinate capabilities or attempt to access tools and data sources that no longer exist in their expected form. Environmental registries are maintenance-intensive but essential for reliable agent execution in real workflows.
How Context Engineering Differs From Prompt Engineering
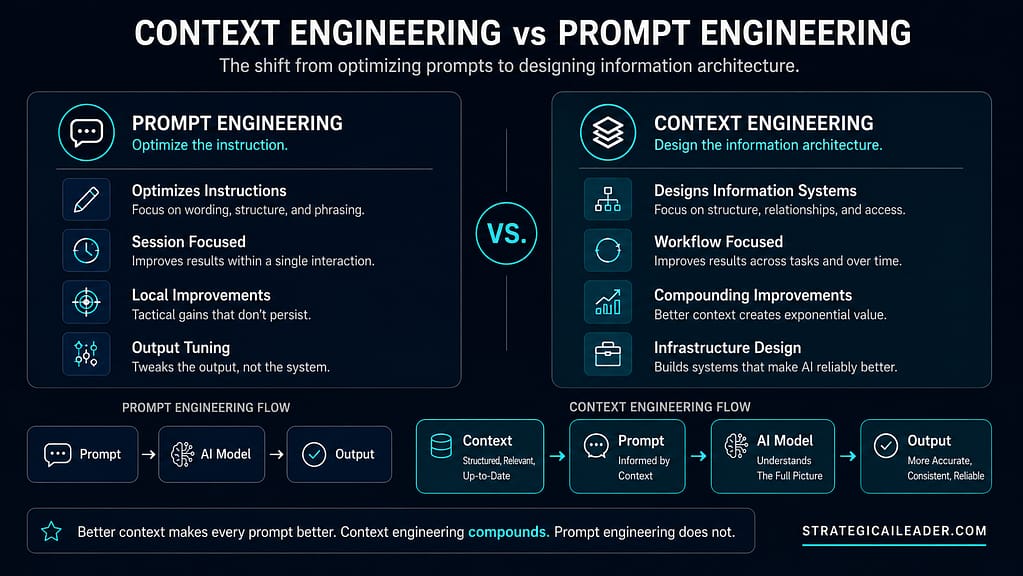
The clearest way to see the difference is through failure modes.
Prompt engineering fails when the instruction is unclear, incomplete, or formatted incorrectly. Fix the instruction and the output improves. The failure is local and the repair is local.
Context engineering fails when the information environment is incomplete, stale, or poorly structured. Fixing the prompt does not help. The repair requires changes to the underlying architecture: the knowledge systems, the memory layer, the environmental registry, or the organizational context that feeds the context window.
These are different problems requiring different skills. Prompt engineering is primarily a writing and reasoning skill. Context engineering is primarily a systems design and information architecture skill.
This is why organizations that invest heavily in prompt training often plateau. They are improving the instruction layer while the information layers beneath it remain unmanaged. The returns diminish because the constraint has shifted. Better prompts cannot compensate for a missing or poorly structured Context Stack.
I expected prompt engineering to scale further than it did. The wall appeared at a predictable point: when the AI started getting confused about context that should have been obvious. That was the signal that the problem had shifted from the instruction layer to the information layer.
| Prompt engineering is the instruction layer. Context engineering is everything the instruction depends on. |
Who Makes a Great Context Engineer?
The role does not require a new hire with a new title, at least not yet. What it requires is someone who can think clearly about information architecture and who understands how AI systems consume context.
The skill set draws from several disciplines that already exist.
Information Architecture
Context engineers need to understand how information should be structured for AI retrieval, not just human readability. They think about taxonomy, relationships between concepts, field structure, and what information needs to be surfaced at which point in a workflow.
Systems Thinking
The Context Stack is a system with dependencies between layers. Changes to organizational context affect how project context is interpreted. Changes to the environmental registry affect what historical context is relevant. Context engineers need to see these dependencies and design for them.
AI Workflow Design
Context engineers understand how agents consume context windows, what triggers context retrieval, how memory layers are populated, and where context gaps produce degraded output. They do not need to be model researchers, but they need a working model of how AI systems use the information they receive.
Documentation Discipline
Context engineering is, in part, a documentation discipline. The best context engineers write clearly, structure information precisely, and maintain systems over time rather than treating documentation as a one-time deliverable.
The professionals I have seen step most naturally into context engineering work come from technical writing, product management, knowledge management, and senior engineering backgrounds where system design and documentation intersect. The title is new. The underlying skills are not.
Context Engineering in Practice: What It Looks Like Inside a Workflow
Abstract explanations of context engineering are easy to follow. Seeing it in a real workflow makes the discipline concrete.
Our content production pipeline at StrategicAILeader is a context engineering system, even though I did not originally design it with that label.
The framework registry is Layer 3 organizational context: every named framework used across articles is registered with canonical definitions, diagram specifications, and usage rules. The entity registry is a parallel system for named concepts. Before any article is generated, the pipeline performs a registry lookup as a blocking step. The AI cannot proceed until it has confirmed which frameworks exist, which definitions apply, and which terminology is canonical.
The article brief is Layer 2 project context: it contains the specific requirements, target audience, keyword targets, and structural specifications for each individual piece. It is structured for AI consumption, not human browsing. Every field exists because the generation step needs it.
The metrics map is Layer 4 historical context: approved data points from past experiments and case studies that the AI can retrieve to support claims. No metric can be used that is not in the map. This eliminates fabrication.
Before we formalized these layers, article production was inconsistent. Each generation started without the information it needed. Sessions required multiple correction rounds. Framework names drifted. Definitions varied. Every output felt like it came from a different system, because from the model perspective, each session did start fresh.
After formalizing the layers, the experience changed. Not because we wrote better prompts. Because the AI had access to the information it needed before generation began.
That is context engineering.
Where Context Engineering Is Going
The discipline is early. Most organizations have not named it, let alone built roles or systems around it.
That will change. As AI deployments move from experiments to production systems, the information architecture problems will become impossible to ignore. Teams will start asking why their agents keep making the same mistakes, why performance degrades over time, why outputs from one session cannot be connected to decisions from the session before.
The answer to all of those questions is context engineering.
Anthropic has formalized the concept in its own research and documentation, defining it as the set of strategies for curating and maintaining the optimal set of tokens during LLM inference. That is a technical framing. The practitioner version is simpler: context engineering is the discipline of making sure AI systems have access to the right information before they begin.
The Model Context Protocol (MCP) is one early infrastructure answer to this problem. MCP creates a standardized way to connect AI models to the data sources and tools that populate the environmental and historical context layers. Organizations that build MCP integrations today are laying the groundwork for context systems that will scale as their AI deployments grow.
The practitioner who understands how to design, build, and maintain these systems, across all five layers of the Context Stack, is a context engineer. The role will become more defined as organizations discover what they are missing.
Quick Wins: Where to Start With Context Engineering
If you are diagnosing context failures in your current AI workflows, start here.
- Audit Layer 2 first. Document the specific project your AI agent is working on, not in narrative form but as structured fields. What is it building? What constraints apply? What decisions have already been made?
- Identify your Layer 3 gaps. What organizational standards, naming conventions, and process documentation should your AI know but currently does not? Make a list. Prioritize by frequency of confusion.
- Build one historical context artifact. Start with a decision log. Record every significant decision made during an AI project, the options considered, and the reasoning for the final choice. Connect this to your next AI workflow as a pre-generation lookup.
- Register your frameworks and entities. If you use recurring concepts across AI workflows, write canonical definitions for them and create a registry. Require the AI to confirm which definitions apply before generating.
- Audit your environmental context. Document which tools, APIs, and data sources your agents have access to. Validate that this registry stays current. Stale environmental context is one of the most common sources of confident but wrong AI output.
The Shift From Prompting to Architecture
Most AI projects treat the model as the variable. Better model, better output. Most AI practitioners treat the prompt as the variable. Better instruction, better output.
Context engineers treat the information environment as the variable. Better context architecture, better output, reliably, across every session, across every AI system that draws from the same information infrastructure.
This shift matters because AI systems are becoming infrastructure, not tools. You do not optimize infrastructure with better instructions. You design it with better architecture.
The context engineer is the person who builds that architecture. The Context Stack is the framework for doing it systematically. And the organizations that invest in this discipline now will have a compounding advantage over those that keep trying to solve information architecture problems with prompt engineering.
The next layer of AI capability is not in the model. It is in what the model knows before you ask.
Frequently Asked Questions About Context Engineering
What is a Context Engineer?
A Context Engineer designs the information systems that AI models and agents use to make decisions. Instead of focusing only on prompts, they build the memory, retrieval, governance, workflows, and knowledge structures that provide AI with the right information at the right time.
What does a Context Engineer do?
A Context Engineer manages the flow of information into AI systems. Responsibilities often include:
- Designing retrieval systems
- Building memory architectures
- Structuring organizational knowledge
- Defining governance and guardrails
- Connecting AI to tools and data sources
- Improving AI reliability and accuracy
The goal is simple: ensure AI works with complete, relevant, and trustworthy context.
What is the difference between prompt engineering and context engineering?
Prompt engineering focuses on how instructions are written.
Context engineering focuses on everything the AI receives before generating an answer, including:
- Business rules
- Historical decisions
- Project requirements
- Knowledge bases
- Tool access
- Organizational standards
Prompts are one part of the context layer. Context engineering manages the entire system.
Why do AI projects fail?
Many AI projects fail because teams focus on models and prompts while ignoring context. When AI lacks access to accurate information, business rules, and organizational knowledge, performance suffers regardless of model quality.
What is a context failure?
A context failure occurs when an AI system receives incomplete, outdated, irrelevant, or poorly structured information. The model may perform exactly as designed, but the missing context leads to poor outputs, incorrect decisions, or unreliable results.
Is context engineering replacing prompt engineering?
No. Prompt engineering still matters.
Context engineering expands the scope beyond prompts. As AI agents become more autonomous, organizations need systems that manage memory, retrieval, governance, and decision support at scale. Prompt engineering becomes one component of a larger context engineering discipline.
Why is context engineering important for AI agents?
AI agents make decisions, use tools, and perform multi-step workflows. Those actions require far more information than a single prompt provides.
Context engineering helps agents:
- Access relevant knowledge
- Use tools correctly
- Follow business rules
- Maintain consistency
- Reduce hallucinations
- Improve decision quality
What skills does a Context Engineer need?
Strong Context Engineers often combine skills from several disciplines:
- Product management
- Data architecture
- Knowledge management
- AI systems design
- Information architecture
- Process design
- Governance and compliance
The role requires systems thinking more than traditional software engineering.
Can non-engineers become Context Engineers?
Yes.
Many of the most valuable context engineering skills involve organizing knowledge, defining business processes, documenting decisions, and designing workflows. Product managers, operations leaders, analysts, and subject matter experts already possess many of these capabilities.
What is the Context Stack?
The Context Stack is a framework for understanding how AI systems receive information:
- Instructions
- Project Context
- Organizational Context
- Historical Context
- Environmental Context
Each layer builds on the layers below it. Weaknesses at any level reduce AI performance and reliability.
How do organizations get started with context engineering?
Start by auditing the information available to your AI systems.
Ask:
- What information does the AI need?
- Where does that information live?
- How is it maintained?
- How is it retrieved?
- Who owns it?
- How is quality measured?
Most organizations discover that their biggest AI challenge is not model capability. It is fragmented knowledge and missing context.
What is the future of context engineering?
As AI agents become common across product development, operations, marketing, customer support, and software engineering, context engineering is likely to become a foundational business capability.
Organizations that build better context systems will often outperform organizations that simply adopt newer models. The competitive advantage increasingly comes from proprietary knowledge, structured context, and operational learning rather than model access alone.
If this framing resonates, subscribe to the StrategicAILeader newsletter. Each issue covers operator workflows, context engineering, decision infrastructure, and AI systems design from inside real implementation cycles. No generic AI commentary. Just what is actually working in production.
Help Support My Writing
Subscribe for weekly articles on leadership, growth, SEO and AI-driven strategy. You’ll receive practical frameworks and clear takeaways that you can apply immediately. Connect with me on LinkedIn or Substack for conversations, resources, and real-world examples that help.
About the Author
I’m Richard Naimy, an operator and product leader with over 20 years of experience growing platforms like Realtor.com and MyEListing.com. I work with founders and operating teams to solve complex problems at the intersection of product, marketing, AI, systems, and scale. I write to share real-world lessons from inside fast-moving organizations, offering practical strategies that help ambitious leaders build smarter and lead with confidence.
I write about:
- AI + MarTech Automation
- AI Strategy
- Context Engineering
- COO Ops & Systems
- Growth Strategy (B2B & B2C)
- Infographic
- Leadership & Team Building
- Marketplace Growth Strategy
- My Case Studies
- Personal Journey
- Revenue Operations (RevOps)
- Sales Strategy
- SEO & Digital Marketing
- Strategic Thinking
Want 1:1 strategic support?
Connect with me on LinkedIn
Read my playbooks on Substack