Anthropic Agent Skills: From Course to App
Anthropic Agent Skills: From Course to Building the DailyRank App
Most people finish an AI course with a full notebook. Few finish with a working system.
You took the DeepLearning.AI agent skills course. You understood tool use, memory layers, and planning loops. You closed the browser, and nothing shipped.
The gap is not your skill level. The gap is the distance between what a course teaches and what production actually demands.
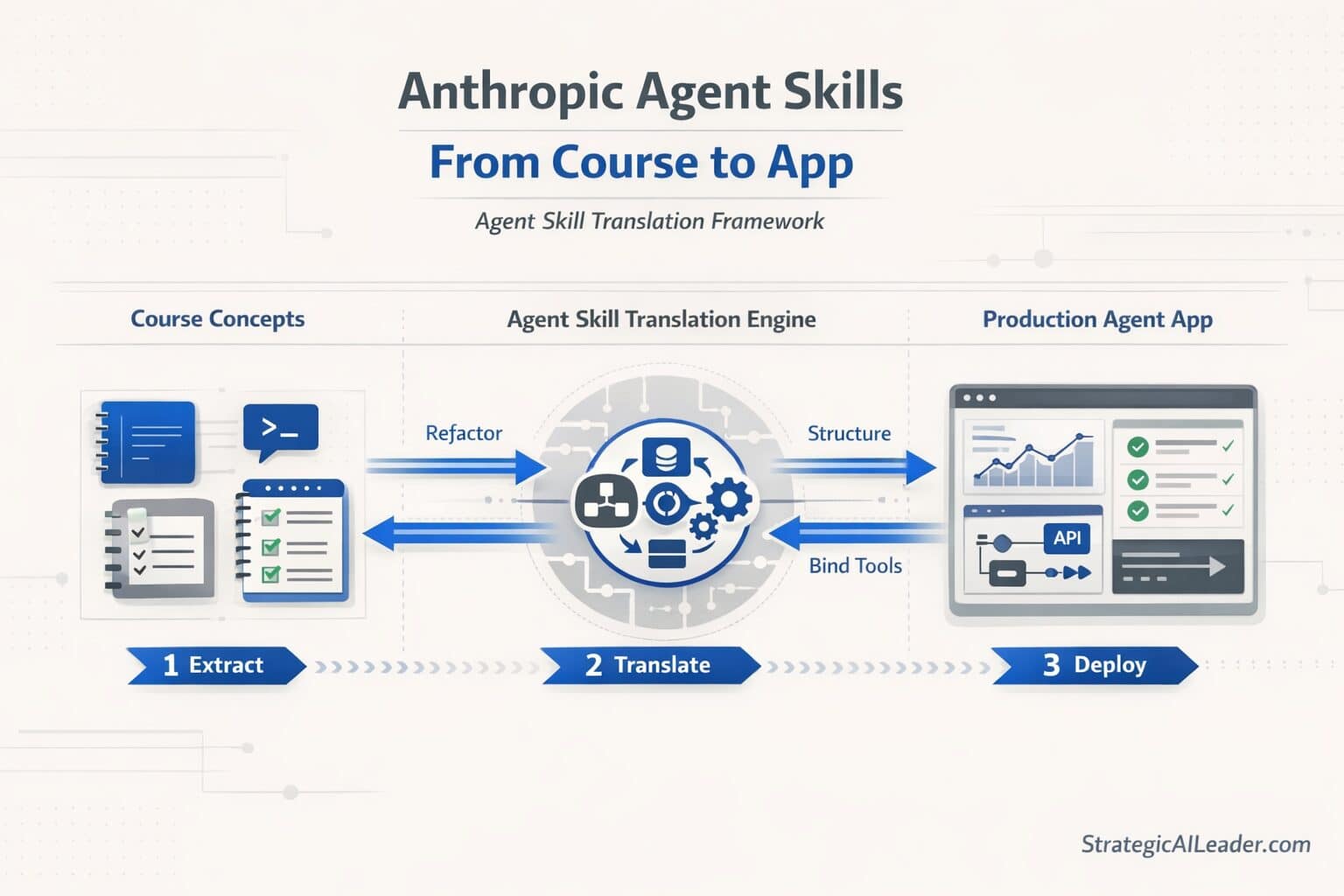
This guide breaks down how Anthropic agent skills translate from concept to a real, functioning puzzle game app called DailyRankTM. Including what breaks along the way, and why most people never fix it.

What are Anthropic agent skills?
Anthropic agent skills are the core capabilities required to build a working Claude-powered agent: structured prompting, tool use, memory, planning loops, and execution control. Together they form the infrastructure layer that turns a language model into a system that can decide, act, and self-correct inside a real workflow.
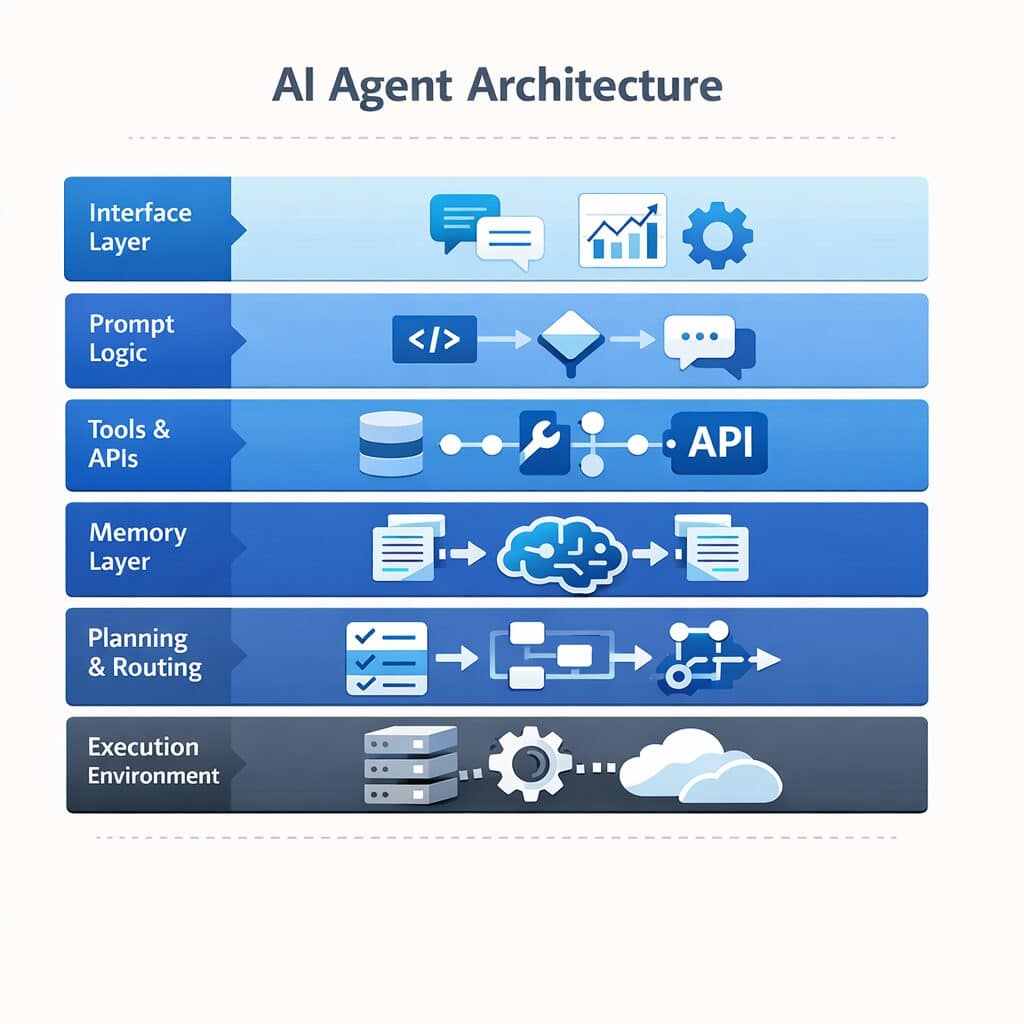
tools, memory, routing, and execution layers inside a production agent system
What Leaders Get Wrong About AI Agents
Here’s the rookie mistake I made early on: I thought an agent was a smarter chatbot.
Wrong. A chatbot responds to what you give it. An agent decides what it needs, calls the right tools, checks the results, and loops without waiting. That difference matters more than most operators realize before they’ve built one.
Three misconceptions slow most operators down:
- Agents = chatbots. Agents are decision systems with a planning layer on top.
- Prompt engineering = agent architecture. Prompts are one piece. Tool interfaces, memory, and execution logic are three more.
- Tool use = automation. Calling a tool is a single step. An agent sequences multiple tools, handles failures, and adapts mid-run.
Dropping these assumptions took longer than expected. The mental model shift happened fast. Rebuilding the approach around it did not.
What Does the DeepLearning.AI Agent Skills Course Actually Teach?
Five infrastructure layers. Most students treat them as theory. Treat them as a build checklist instead, and the course becomes something you can actually ship from.
1. Structured Prompting
Your agent needs consistent, parseable outputs. Structured prompting tells the model to return JSON, follow schemas, and separate its reasoning from its response. Skip this and your agent outputs become unpredictable garbage downstream.
2. Tool Use
Claude can call external APIs when you define the tool interface correctly. A tool is a function the model can invoke: a database query, a web search, a CRM lookup. On the first build, I left parameters loosely described and Claude started inventing field names. Tight schemas prevent tool hallucination. Loose ones cause it. For a broader look at what makes LLM tools fail in real deployments, Building AI Tools With LLMs covers the production gap most teams miss.
3. Memory
Context disappears between agent calls unless you build memory in deliberately. Short-term memory holds context within a session. Long-term memory persists across sessions via vector stores or databases. Build neither and every agent call starts from scratch.
4. Planning Loops
Blind execution is expensive. Before acting, a planning prompt asks:
- What do I need?
- What tools do I have?
- What order makes sense?
- Claude reasons through the plan first, which cuts errors on chained tool calls significantly.
5. Execution Control
Guardrails matter more than most operators expect. Execution control means setting max iterations, handling tool failures gracefully, and routing unexpected outputs without crashing the whole workflow.
How Do You Build an Anthropic Agent Architecture in a Real App?
Six layers map to an actual system built using the Anthropic API:
Intent Parser: A prompt reads user input and classifies the task type. Output: structured JSON.
Planner: A second prompt receives the classified intent and generates a step-by-step plan before any tool runs.
Tool Router: Logic reads the plan and maps each step to the correct tool. Each tool carries a strict JSON schema.
Execution Layer: Claude calls the tools in sequence, checks outputs, and retries on failure (up to three attempts).
Memory Layer: Session state stores prior tool results. A vector store handles long-term retrieval when context exceeds the window.
Response Builder: A final prompt compiles tool outputs into a clean, human-readable response.
Six layers. One loop. The first version took three weeks longer than planned, mostly spent debugging the handoff between the Tool Router and Execution Layer. When those two talk cleanly, the rest of the system holds.
What is the Structured Tool Agent Loop (STAL)?
The Structured Tool Agent Loop is a six-step agent architecture framework: intent detection, planning, tool routing, execution, memory update, and response synthesis. Each step handles one job. Separating planning from execution is the critical design decision that improves tool routing reliability and reduces agent failure rates in production.
What Breaks When Claude Agents Reach Production?
No one warns you about this part:
Tool hallucination: Claude invents tool parameters when schemas are vague. Enforce strict JSON schemas with field-level descriptions. This was the first thing that broke in production and the last thing expected.
Schema drift: Model outputs shift subtly across API versions. Validate every tool response against a schema before it moves downstream.
Latency stacking: Chaining five tools adds time fast. Parallelize independent tool calls where the workflow allows it.
Context overflow: Long agent runs hit the token ceiling. Summarize prior steps before they bloat the context window.
State inconsistency: Two concurrent agent runs modifying the same data create conflicts. Lightweight locking or queue-based execution fixes this.
These failure modes are consistent across agent architectures. What Happened When Model Context Protocol Fixed AI Decisions documents a real production case where context structure, not model quality, drove most of the breakage.
The Structured Tool Agent Loop (STAL)
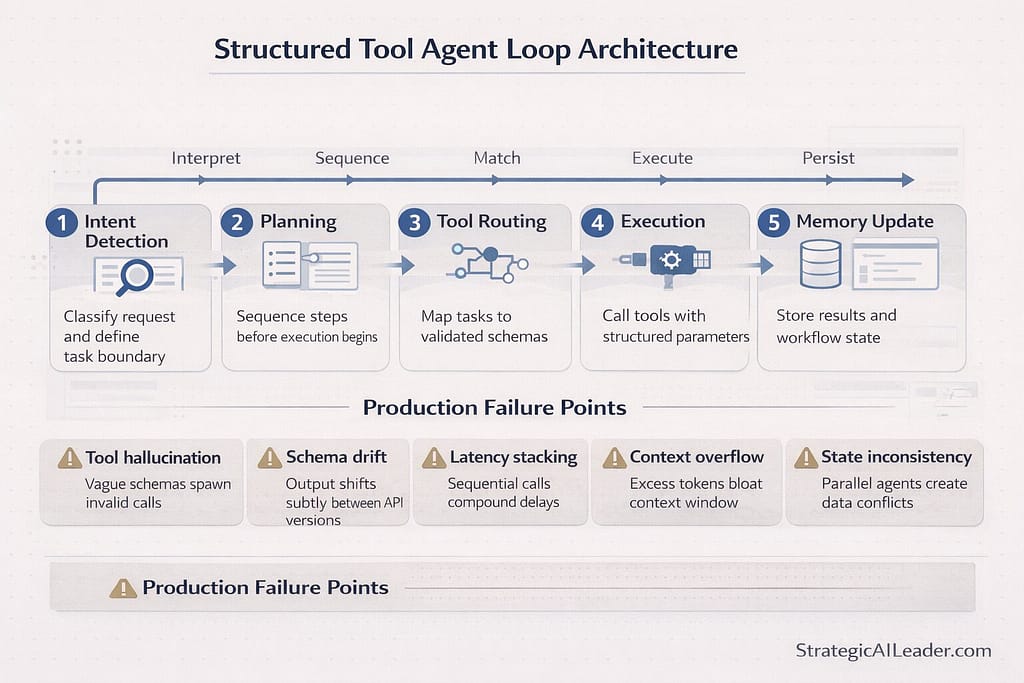
After working through those failures, a reusable framework emerged from the wreckage.
Call it the Structured Tool Agent Loop:
Step 1: Intent Detection. Classify the task with a structured prompt.
Step 2: Planning. Generate a step plan before executing anything.
Step 3: Tool Routing. Map plan steps to tools using schema-enforced interfaces.
Step 4: Execution. Run tools, validate outputs, retry on failure.
Step 5: Memory Update. Persist results to session and long-term stores.
Step 6: Response Synthesis. Compile a clean output from tool results.
STAL works across internal ops workflows, customer-facing agents, and data pipelines. Swap the tools, keep the loop. Fair warning: the framework did not survive the first production deployment unchanged. Step 3 (Tool Routing) needed an error-handling layer that was not planned for. Build that in from the start.
Quick Wins You Can Apply This Week
- Add JSON output contracts to every prompt feeding downstream logic.
- Separate reasoning from response: have Claude think in one block, output in another.
- Log every tool call with inputs and outputs. Debugging without logs costs hours.
- Wrap external APIs as callable tools with strict schemas before connecting them to Claude.
- Add a planner prompt before execution: one extra API call saves ten failed runs.
- Build a session memory object that carries forward key results between calls.
The Real Shift
Anthropic agent skills only become valuable once they run inside a decision loop connected to tools and memory. The course gives you the ingredients. Production demands you build the kitchen, and the kitchen catches fire a few times before it runs clean.
How do Anthropic agent skills connect to business ROI?
Agent skills create ROI only when they reduce manual steps inside real decision workflows. A working agent cuts execution time on repeatable tasks, reduces tool selection errors through schema enforcement, and compounds value as memory layers accumulate session context across runs. Without that loop, agent skills stay theoretical.
Operators who ship agents treat each layer, planning, tool use, memory, and execution, as a distinct engineering problem. Solve each one. Wire them together. Iterate fast. No single layer is hard. Connecting them without breakage is. For context on how AI infrastructure connects to measurable business outcomes, read AI ROI Strategy: The Important Truth Leaders Need Now.
Want More Like This?
Got a framework you can actually use from this? Subscribe to the StrategicAILeader newsletter. Every week: operator-grade AI strategy, implementation breakdowns, and zero fluff.
Subscribe at StrategicAILeader.com and get the next issue straight to your inbox.
Connect with me on LinkedIn and drop a comment: what’s the hardest part of shipping your first agent?
Related Articles
How I Used Growth Strategy to Design a Daily Game Loop
he Truth About AI-Driven SEO Most Pros Miss
Intent-Driven SEO: The Future of Scalable Growth
SEO Strategy for ROI: A Better Way to Win Big
Future of SEO: Unlocking AEO & GEO for Smarter Growth
Skyrocket Growth with Keyword Strategy for Founders
Unlock Massive Growth with This 4-Step SEO Funnel
AI Traffic in GA4: How to Separate Humans vs Bots
About the Author
I’m Richard Naimy, an operator and product leader with over 20 years of experience growing platforms like Realtor.com and MyEListing.com. I work with founders and operating teams to solve complex problems at the intersection of product, marketing, AI, systems, and scale. I write to share real-world lessons from inside fast-moving organizations, offering practical strategies that help ambitious leaders build smarter and lead with confidence.
I write about:
- AI + MarTech Automation
- AI Strategy
- COO Ops & Systems
- Growth Strategy (B2B & B2C)
- Infographic
- Leadership & Team Building
- My Case Studies
- Personal Journey
- Revenue Operations (RevOps)
- Sales Strategy
- SEO & Digital Marketing
- Strategic Thinking
Want 1:1 strategic support?
Connect with me on LinkedIn
Read my playbooks on Substack