Building AI Tools With LLMs: A Practical Guide Leaders Need
Why Most AI Tools Fail in Production and What Leaders Must Do Differently
A sales team spent months building AI tools with LLMs to score leads. The demo looked sharp. Leadership loved the charts. The model hit every benchmark that mattered in testing.
By the end of the first week after launch, reps had returned to their spreadsheets.
The scores felt opaque. The tool added friction. Accessing information they already understood required extra steps. Conversion slipped. Trust disappeared.
Every AI deployment I’ve built follows the same pattern. I saw this most clearly while building AI-assisted decision systems inside MyEListing, a commercial real estate marketplace, and while testing forecasting and inventory signals in a small retail operation, Lia’s Flowers, where errors showed up as waste within days, not quarters. In environments where mistakes surface immediately, failure never starts with the model. Leaders who treat AI like deterministic software create failure, because AI is a probabilistic system that proves itself only through real use.
Most AI pilots fail to meet expectations because the technology works, but the systems around it do not. Traditional software ships with known behavior. AI systems ship with hypotheses. You validate those hypotheses only by deploying them into live workflows and testing relentlessly.
Building AI tools with LLMs succeeds when you treat development as disciplined experimentation rather than traditional software delivery. The model you choose matters far less than how quickly you learn from failure.
Across the AI-assisted tools I’ve shipped in growth, forecasting, and decision support, most early versions failed fast. The technology wasn’t wrong. The surrounding system was incomplete. Workflow friction, vague requirements, and missing feedback loops caused more damage than model limitations ever did.
What Leaders Get Wrong About AI Tools
Most AI initiatives fail for reasons unrelated to intelligence.
Overconfidence in Demos

Leaders make their first mistake when they believe that prototypes predict production success. A prototype proves that a model can perform a task in isolation. The same prototype does not prove that people will trust it, rely on it, or use it under pressure.
I watched a fraud detection system flag 60% of legitimate transactions in its first week. The model worked flawlessly in testing. No one tested it against actual transaction volume and patterns under production load. The ops team stopped reviewing alerts by day three. When users must investigate constant false alarms, they stop paying attention altogether. A system that cries wolf trains people to ignore it (e.g., think Ring Doorbell).
Demos prove possibility but not reliability. Only real-world deployment and continuous testing reveal reliability.
Model Fixation
The second mistake is obsessing over which LLM to use while the real problems sit upstream. Teams spend weeks debating model selection. Meanwhile, prompts contain conflicting instructions. Inputs lack context. Outputs arrive too late to influence decisions. Research on LLM operational failures shows that most issues attributed to model quality stem from operational design gaps.
Model choice matters, but operational clarity determines success. This failure mode is not technical. It is a leadership decision about where attention gets spent.
Treating AI as a Feature
Teams make the third mistake when they assume intelligence bolts cleanly onto existing processes. LLM-powered tools behave like systems because they are systems. They require guardrails, monitoring, human review, and continuous adaptation. Every time I’ve seen a team underestimate the work, they’ve scoped AI as a UI enhancement rather than a decision layer that reshapes how people operate.
AI tools demand operational discipline, not optimism about model capabilities.
The Learning Loop Behind Successful AI Products
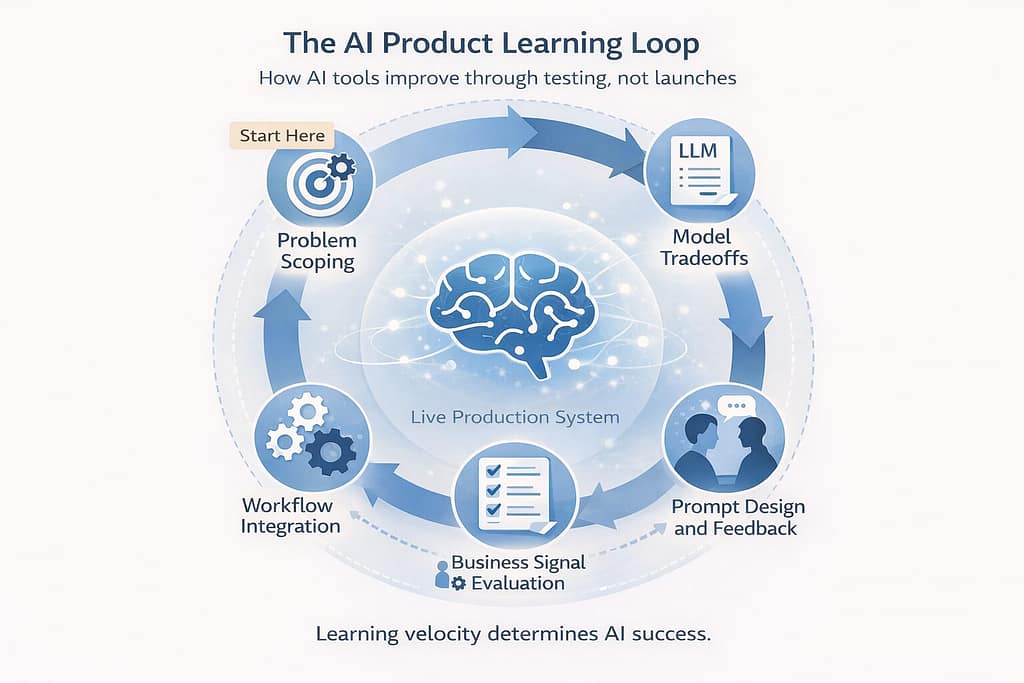
Every effective AI initiative follows the same learning loop. The loop runs continuously, not as a one-time checklist. Five phases define the cycle:
- Problem scoping before solution scoping
- Model selection through capability tradeoffs
- Prompt and feedback adaptation where most work lives
- Business signal evaluation beyond technical metrics
- Workflow integration where tools survive or die
Scope the Problem Before the Solution
The fastest way to fail is to start with “let’s use AI for X.”
The work starts with the decision you want to support. Identify who makes it. Determine when the decision gets made and who makes it. Understand how decision-makers respond when the signal feels wrong. In growth systems, clarity on these questions matters more than any benchmark. Teams often say they want AI for customer support when the real issue is that a small set of repeat questions consumes most of the team’s time.
Narrow scoping accelerates learning. In small retail environments like a florist, forecasting errors are not abstract metrics. They show up as spoiled inventory, missed deliveries, and margin erosion within a week, which forces discipline around feedback and iteration. While applying AI-assisted forecasting in a small retail operation, precision in scope mattered more than model capability because mistakes translated directly into waste. In a marketplace environment like MyEListing, the same principle applies. Learning happens fastest when feedback loops are tight.
Leaders consistently underestimate how much the generative AI development process depends on problem clarity.
Select Models Based on Tradeoffs, Not Benchmarks
Most teams should begin LLM application development with general-purpose models (e.g., See resource section below) and strong prompts. Fine-tuning has a place, but not at the beginning.
During early testing, I deliberately chose smaller, faster models to maximize iteration speed. Learning velocity beats raw capability every time. Once I fully understood the problem, upgrading models made sense. Starting with the most expensive option would have slowed experimentation and delayed insight.
Model selection is a business decision. Volume, latency, cost, and iteration speed matter more than leaderboard rankings.
Adapt and Align Through Prompts and Feedback
Most of the work lives here.
Prompt engineering for business is executable logic. Production prompts are versioned code, not creative writing. They define constraints such as “never recommend products not in inventory,” expectations such as “return JSON with confidence scores,” and failure modes such as “if uncertain, return null and flag for review.”
Early prompts are short. Production prompts grow long and precise as edge cases emerge.
I once spent days debugging malformed outputs before realizing a single example in the prompt had inconsistent formatting. The model copied the error perfectly. Fixing the example fixed the system.
Prompts evolve constantly. They require testing, version control, and fast rollback. When something breaks, clarity usually fixes it faster than switching models. Systematic research on prompt engineering demonstrates that structured approaches to prompt design, including constraint definition and failure mode specification, significantly improve model reliability in production environments.
Fine-tuning improves consistency and makes behavior predictable when prompts alone no longer suffice, but fine-tuning does not improve intelligence.
Human oversight is not optional. Internal testing never reveals how people actually work. Real users surface trust gaps, workflow mismatches, and silent failure modes. When override rates exceed 30%, a pattern I’ve observed across six deployments, the system has already lost user trust. Leadership notices the decline in adoption long after the breakdown begins.
Evaluate Using Business Signals, Not Technical Scores
Accuracy alone does not predict success.
Adoption shows whether the tool fits the workflow. I’ve watched usage drop sharply after launch because accessing the tool felt cumbersome, even when users liked the output. Fixing placement restored adoption.
Usefulness shows up in acceptance rates. Tools people constantly second-guess fail regardless of accuracy. Tools that explain uncertainty often outperform more precise black boxes because LLM hallucinations undermine trust when models generate confident but incorrect outputs.
Workflow impact is the ultimate test. AI that saves time in one step but adds friction elsewhere destroys value.
One system I deployed looked successful by every internal metric. Accuracy cleared thresholds. Latency stayed within limits. Early testers approved the outputs. Two weeks later, usage dropped quietly without complaints. When we observed real behavior, we discovered users were exporting results into spreadsheets to double-check them before acting. The AI produced technically correct outputs, but decision-makers hesitated when they needed to act. That hesitation erased the value. No test environment would have revealed that behavior. Only production use made it visible.
Integration Determines Survival
Embedding AI into workflows matters more than intelligence.
Usage collapses if users must leave their flow to consult an AI tool. Effective integration places AI directly where decisions happen. In marketplace environments like MyEListing, decision support only works when insights surface directly inside listing review, lead routing, or pricing workflows, not in separate dashboards that no one has time to check. I’ve seen identical intelligence fail in dashboards and succeed once embedded into existing workflows.
You are building an assist, not a destination.
Deploying LLM Applications Is the Beginning
Deploying LLM applications marks the start of learning, not the end of development.
Models drift. User behavior shifts. Prompts that worked last quarter quietly degrade. Monitoring output quality, corrections, and feedback patterns becomes ongoing work. Teams that treat AI as “set and forget” watch tools decay until users abandon them.
Continuous iteration is the cost of reliability.
Scale Only After Proof
Mature AI tools become orchestrated systems with retrieval layers, routing logic, and safety checks. At this stage, most teams introduce retrieval-augmented generation (AKA RAG). Rather than training the model on proprietary data, retrieval systems ground responses in live business context such as listings, inventory, policies, or historical decisions. This approach improves reliability and trust without changing the underlying model. In practice, RAG solved more problems for me than fine-tuning ever did, because it reduced hallucinations and aligned outputs with how teams already reason about data. Leaders often assume training the model is the solution, when grounding the model in the right context delivers faster and safer gains. Complexity belongs later.
I’ve seen teams spend months architecting for scale before confirming whether users even wanted the tool. Starting simple creates space to learn. Scale follows proof, not ambition.
Why AI Is a Testing Discipline

Every AI initiative is a sequence of hypotheses. The fastest learning I’ve seen came from teams who treated each deployment like a live experiment and watched behavior daily, not from teams who waited for quarterly reports or model reviews.
You observe where it fails. You adjust constraints, prompts, and guardrails. You test again. The cycle never ends.
Teams that learn fastest win not because they have better models, but because they treat deployment as a learning event rather than a finish line.
Traditional software rewards certainty. AI rewards humility.
Building AI tools with LLMs is not a one-time build. The work is a continuous testing discipline.
Key Takeaways
- Building AI tools with LLMs succeeds through disciplined testing, not just model selection.
- The generative AI development process breaks down when teams ignore workflows and feedback loops.
- Prompt engineering for business functions as executable logic, not creative writing exercises.
- Fine-tuning improves consistency and predictability, not intelligence or capability.
- Human oversight is essential for trust, safety, and continuous learning.
- Deploying LLM applications starts the learning cycle rather than ending it.
- Integration and adoption matter more than raw model capability or benchmark performance.
Conclusion
Building AI tools with LLMs requires a shift in how leaders approach technology. Success comes from treating AI as a system that must be tested and refined, not software shipped complete.
The model matters less than the discipline you bring to learning what works. Teams that invest in feedback, integration, and iteration outperform those chasing benchmarks.
Your AI tool will need changes after launch. The only question is whether you’ve built systems that let you learn and adapt fast enough to keep it functional.
Resources for Teams Building AI Tools With LLMs
Teams often ask where AI tools actually get built, tested, and adapted in practice. Access to models and infrastructure is rarely the constraint. The more complex work involves deciding what behavior needs to change, how to evaluate it in real workflows, and how to operate the system after deployment.
The following platforms commonly support different stages of building AI tools with LLMs.
- OpenAI
- Frequently used for early experimentation and rapid iteration during LLM application development. Teams often start here to test prompts, evaluate decision support use cases, and validate whether AI adds value before investing in heavier infrastructure.
- Hugging Face
- A widely used hub for open models, datasets, and experimentation. Many teams use it to explore domain-specific behavior, prototype fine-tuning approaches, and test how different model architectures behave before committing to production deployment.
- AWS (Bedrock and SageMaker)
- Commonly used when governance, security, and integration with enterprise systems matter. These services support deploying LLM applications, managing fine tuning large language models, and operating AI systems inside existing cloud environments.
These platforms lower the barrier to entry. They do not solve workflow integration, trust, governance, or adoption. Teams that succeed treat these tools as enablers inside a broader AI product development framework, not as solutions on their own.
Learn More About Generative AI and LLMs (For Executives)
Leaders do not need to learn how to train models to lead effective AI initiatives. They need to understand how generative AI systems behave, where they fail in production, and how to structure teams, workflows, and governance around them.
The resources below are designed for executives, operators, and product leaders who want to build informed judgment about generative AI and large language models without diving into technical implementation.
MIT Sloan Management Review focuses on the organizational impact of generative AI, including operating models, decision-making, and why many AI initiatives fail to deliver expected outcomes. This is one of the strongest sources for understanding AI at the system and leadership level rather than the tooling level.
Harvard Business Review covers leadership implications, workforce dynamics, and governance considerations tied to generative AI. The articles emphasize how leaders should think about adoption, incentives, and risk rather than how engineers should build systems.
DeepLearning.AI provides executive-friendly education centered on how AI systems behave in real organizations. The content focuses on mental models, standard failure modes, and realistic expectations for AI initiatives. It is beneficial for leaders who want clarity without learning to code.
AI for Everyone by Andrew Ng is explicitly designed for non-technical leaders. It explains how AI works at a conceptual level, how to scope projects, and how to avoid organizational and governance mistakes that cause AI initiatives to fail.
Frequently Asked Questions about Building AI tools with LLMs
What is the first step in building AI tools with LLMs?
Start by defining the decision you want to support, not the model you want to use. Identify who makes the decision, when they make it, and what they do when the signal feels wrong. Teams that skip this step often build technically impressive systems that fail to influence real behavior.
Do you need to fine tune large language models to build AI products?
No. Most teams succeed without fine-tuning. Prompt engineering for business and clear constraints usually handle early needs. Fine-tuning becomes useful when you need consistent structure, predictable formatting, or domain-specific behavior that prompts alone cannot deliver reliably. It improves consistency, not intelligence.
Why do so many AI pilots fail after launch?
According to MIT research, 95% of AI pilots fail to meet expectations. The most common reasons are workflow friction, lack of trust, and missing feedback loops, not model quality. AI systems fail when teams treat them like deterministic software instead of probabilistic systems that require observation and iteration.
How should teams evaluate LLM application development success?
Evaluate success using business signals, not just technical metrics. Adoption shows whether the tool fits the workflow. Acceptance rates reveal trust. Workflow impact determines whether the tool reduces friction or adds it. Accuracy matters, but it does not predict value on its own.
What role does human in the loop AI play in production systems?
Human oversight is essential for trust, safety, and learning. Feedback loops reveal where models fail, where users hesitate, and where workflows break. When override rates exceed roughly 30%, teams should investigate immediately. That level of friction signals a system problem, not a tuning issue.
Is deploying LLM applications the final step?
No. Deploying LLM applications marks the beginning of the learning cycle. Models drift, prompts degrade, and user behavior changes. Teams must monitor outputs, collect feedback, and iterate continuously. AI systems that do not evolve decay until users abandon them.
How does workflow integration affect adoption?
Integration determines survival. AI tools that require users to leave their existing workflow rarely succeed. Systems perform best when insights surface directly where decisions happen, such as inside marketplaces, CRM flows, pricing tools, or operational dashboards.
Stay Connected
I share new leadership frameworks and case studies every week. Subscribe to my newsletter below or follow me on LinkedIn and Substack to stay ahead and put structured decision-making into practice.
Related Articles
AI Task Analysis: How Top Performers Cut Workflow Time 40%
The AI Trap That Makes AI Change Risk Invisible
The Truth About AI Native Content Systems and Visibility
Understanding Model Context Protocol | A Practical Guide for AI Teams
AI Visibility Systems: The New Era of Search Control
Agentic Browsers Explained: The Truth About AI Search
Claude Skills vs MCP: Inside the New AI Capability Layer
The GEO Operating System: A New Model for AI Visibility
Hybrid AI Agent Systems: The Leadership Edge in Automation
The Ultimate AI Agent Strategy for Leaders Who Want ROI
About the Author
I write about:
- AI + MarTech Automation
- AI Strategy
- Context Engineering
- COO Ops & Systems
- Growth Strategy (B2B & B2C)
- Infographic
- Leadership & Team Building
- Marketplace Growth Strategy
- My Case Studies
- Personal Journey
- Revenue Operations (RevOps)
- Sales Strategy
- SEO & Digital Marketing
- Strategic Thinking
Want 1:1 strategic support?
Connect with me on LinkedIn
Read my playbooks on Substack