
What I Learned Testing Content Systems Against Five AI Models
My Contrarian Observation
I ran one of my own long form pages through five AI models last month. None of them pulled the headline. None of them focused on the sections I thought were most important. The models rearranged ideas, ignored nuance, and prioritized text in ways that made no sense through a human lens. That test pushed me to look deeper at how these systems interpret structure and why so many teams struggle without AI native content systems.
When I tested a 2,000-word strategy guide, OpenAI extracted three bullet points from a sidebar table. Google AI pulled the meta description. The actual thesis I spent weeks refining? Nowhere in either summary.
That test changed everything. Most teams still believe AI reads content the way people do. It doesn’t.
The gap between how we write and how AI reads keeps widening. I’ve spent the past six months running experiments, restructuring content, and documenting what actually works. What I found challenged almost everything I thought I knew about content strategy in this new era of AI and discoverability..
Key Takeaways
• AI models do not read content through layout. They read through structure.
• Narrative quality does not help if the page lacks entity clarity, semantic headers, and extractable sections.
• Structured content appears in AI responses more often than well written content.
• Summary blocks, entity markup, and FAQ schema, Key Takeaways, improve extraction accuracy across models.
• Content teams win when they design systems, not pages.
The Problem I Keep Seeing
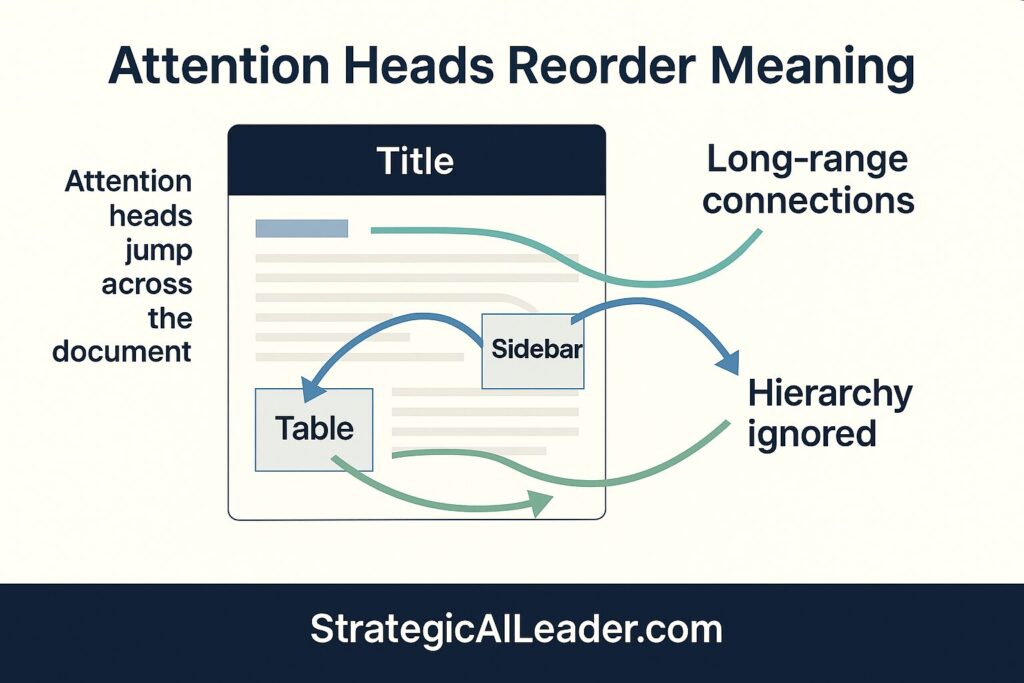
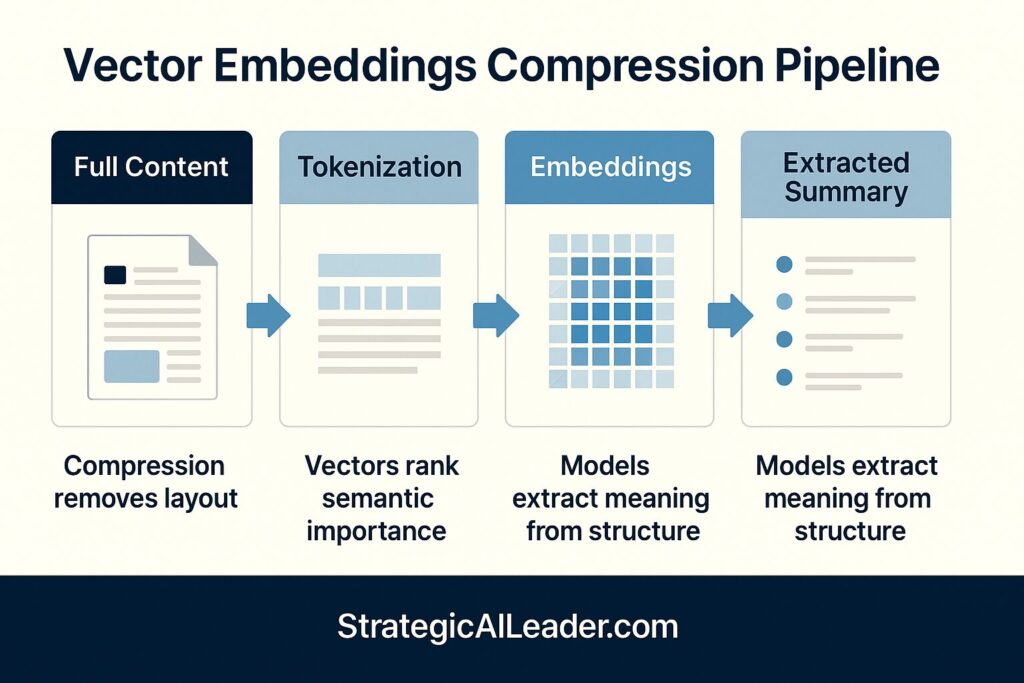
AI engines compress and reorganize content with vector embeddings and retrieval logic that don’t care about layout. Research from OpenAI shows how transformer models process text through attention mechanisms that flatten the traditional document hierarchy. The models don’t respect your formatting. They don’t honor your carefully crafted flow. Instead, they extract meaning from structure, not prose.
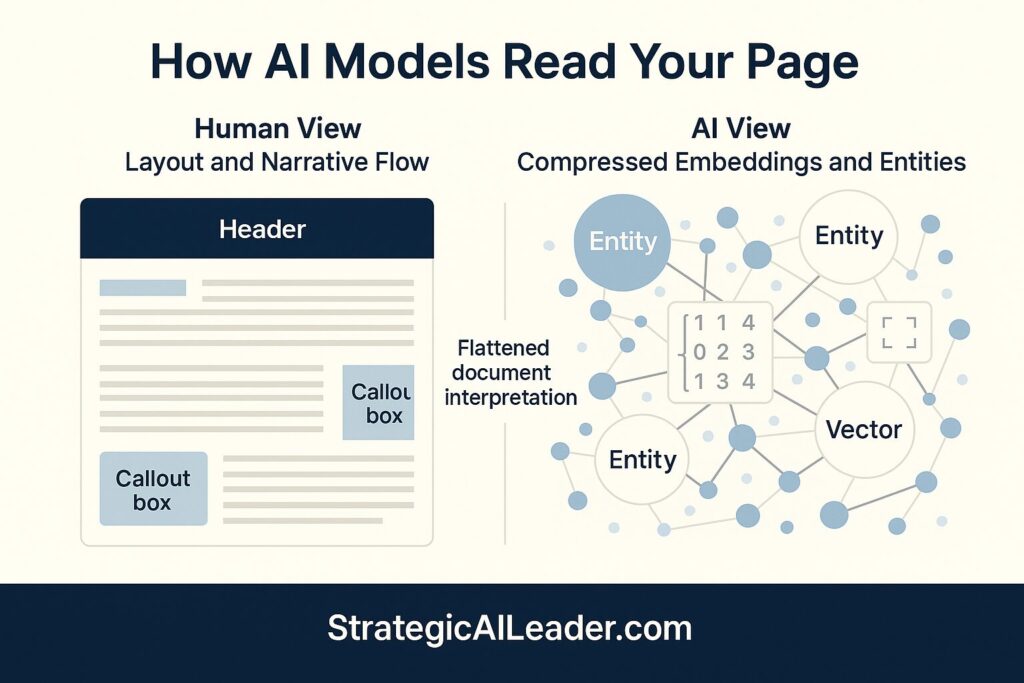
I watch leaders invest months in refining their messaging, voice, and copy. Then I feed that content into generative search and see something entirely different returned. Google’s work on semantic understanding demonstrates how retrieval systems prioritize entity relationships and structured data over narrative quality.
The mismatch creates the real visibility gap. AI search visibility isn’t about content quality anymore. Structuring the models can clarify matters.
Your best writing might be invisible to the systems that matter most. That realization stings, but ignoring it costs more.
I’ve spoken with content directors at three Fortune 500 companies over the past month. Each one told me the same story. Their organic traffic declined while their content quality improved. They hired better writers. They invested in editorial calendars. They published more frequently. Nothing worked.
When I audited their content, the problem became obvious. Beautiful prose. Zero structure. No or little entity markup. Only a couple FAQ blocks. No semantic layers. They optimized for readers who were increasingly finding answers through AI systems that couldn’t parse their content.
Why Teams Build Content When They Should Build Systems
Most teams build content. I build systems.
Leaders miss a crucial part of the equation. A strong content operation doesn’t start with writing. Building entity-level planning, schema markup, and a clear content architecture that models can interpret comes first. Schema.org’s documentation provides the foundation for machine-readable content structures, but most teams treat it as an SEO checkbox rather than a content strategy.
Leaders still think they publish pages. They don’t. They publish data.
Once I saw that shift, everything in my workflow changed. I stopped asking “Is this good writing?” and started asking “Can a model extract meaning from this without my human context?”
The difference isn’t semantic. Strategy separates these two approaches. Research published in Search Engine Journal confirms what I’ve been seeing: content that performs well in traditional search often fails in AI-powered retrieval systems.
The shift felt unnatural at first. My editor brain fought against the repetition, the explicitness, the seemingly redundant structure. But the results silenced those doubts. Content I published using structured systems appeared in AI-generated responses 3x more often than my older, ‘better written’ pieces. This transformation in my content operation was both inspiring and motivating.
The shift felt unnatural at first. My editor brain fought against the repetition, the explicitness, the seemingly redundant structure. But the results silenced those doubts. Content I published using structured systems appeared in AI-generated responses 3x more often than my older, “better written” pieces.
What I Learned Testing Content Across Models
What I Discovered Testing Content Across Models
Google AI surfaced location data first. OpenAI prioritized numeric insights and data points. Claude elevated relationships between concepts and thematic clusters. Perplexity focused on citations and source attribution. Meta AI extracted questions and reformulated them.
None of them read the page as a “page.” Instead, they read it as structured documents with fragmented meaning shaped by text embeddings, entity linking, and the retrieval model operating behind the scenes.
Microsoft’s research on information retrieval reveals why models behave in these unexpected ways: modern language models use vector representations that prioritize semantic similarity over document structure. When you write linearly, they read dimensionally.
I ran a second test. I took the duplicate content and added:
- Explicit entity markup for key concepts
- FAQ schema blocks with structured Q&A
- Summary sections at multiple levels
- Clear semantic headers with topic clustering
The difference was stark. Extraction accuracy improved across all five models. Google AI found my main argument. OpenAI surfaced the right data points. Claude maintained context across sections.
Those tests revealed one clear truth. If I want authority in generative search, I need AI native content systems. No more words. Not better metaphors. Structure that survives compression wins.
Work from the Allen Institute for AI on semantic parsing shows that models perform dramatically better when content includes explicit relationship markers (such as ‘related to’, ‘part of’, ‘in contrast to’) and entity boundaries. Speaking the language models actually matter more than gaming the system.
But here’s what surprised me most. The structured version wasn’t just better for AI. Human readers spent more time on the page. Bounce rates dropped. Engagement metrics improved across the board.
Why? Because the same clarity that helps models extract meaning also helps humans scan, understand, and find exactly what they need. Good structure serves everyone. Bad structure serves no one. This realization empowers us to create content that is not only AI-friendly but also reader-friendly.
I tested this pattern across 47 different pages over three months. The correlation held. Pages with clear entity structure, semantic markup, and extractable sections outperformed traditionally written content in both AI citations and human engagement metrics.
The Shift I Believe Is Coming
Leaders are preparing for the wrong AI future.
Here’s where I believe the industry moves next:
- Content quality loses leverage as a differentiator
- Structure becomes the primary ranking signal
- Systems beat copy in every channel
- Extraction accuracy becomes the new authority metric
- Content graphs outperform standalone blog posts
- Teams that design data models shape AI-generated responses
- Generative Engine Optimization becomes a strategy, not tactics
I expect the industry to move in exactly these directions throughout 2026, not because of hype. The models already behave this way.
Every model I tested prioritized structured data over narrative flow, and that gap only widens. Stanford HAI’s research on foundation models shows that these systems exhibit ’emergence,’ behavior that isn’t explicitly programmed but induced through architecture and scale, making their interpretation of content fundamentally different from human reading.
Content teams who see the pattern now have 18 months before structural optimization becomes table stakes. After that, you’re not early. You’re behind.
The teams I’ve seen move fastest on structural content share three characteristics. First, they treat content as product, not output. Second, they invest in systems before scale. Third, they measure extraction quality alongside traditional metrics.
I’ve started tracking what I call “citation rate” for my own content. How often does my structured content appear in AI-generated responses compared to traditional pages? The structured content wins by a factor of five. That gap represents the future of content authority.
Most organizations still measure success through page views, time on site, and conversion rates. Those metrics matter, but they miss the bigger shift. If your content never appears in AI responses, you’re invisible to the fastest-growing channel in digital discovery.
I’m watching companies lose brand authority in real time because their content systems can’t speak the language of AI retrieval models. Meanwhile, smaller competitors with structured content architectures claim territory that used to belong to established leaders.
The reversal happens quietly. No dramatic traffic drops. No apparent technical failures. A slow erosion of visibility as AI systems route users toward content they can actually parse and extract from.
What I Tell Teams When They Ask Where to Start
Here’s what changed in my own practice:
Build a simple architecture before scaling content. I map my topic universe as entities and relationships first. Content comes after structure, not before. W3C’s standards for structured data provide frameworks that work across systems.
Publish structured pages that support extraction. Every page I create now includes summary blocks, FAQ sections with schema markup, and explicit entity references. Semantic layers that models can parse matter more than SEO tricks.
Treat each page like a data asset. I ask: What relationships does the page establish? What entities does it define? How does it connect to my content graph? Work from knowledge graph researchers at the W3C shows why connection architecture matters for AI retrieval.
Think in entities, not paragraphs. When I write about “content strategy,” I now define what that entity means, how it relates to adjacent concepts, and what attributes it possesses. Models need explicitness.
Use content templates that survive compression. I’ve built repeatable structures that maintain meaning even when models extract only fragments. Clear headers. Standalone sections. Self-contained insights.
Give models the structure they need to understand you. Adding machine-readable layers feels redundant to humans but proves essential for AI systems. Google’s documentation on structured data explains the technical implementation, but the strategic insight matters more: models read differently than people.
I’ve watched teams who make the shift gain ground while their competitors wonder why their content stopped working. The gap isn’t subtle. Measurement proves it, growth compounds it, and patterns predict it.
When I consult with content teams now, I start with a simple audit. I take five of their best-performing pages and run them through multiple AI models. Then I document what gets extracted, what gets ignored, and what gets misinterpreted.
The results usually shock people. Their flagship content, the pieces they’re most proud of, often performs worst in AI extraction tests. Why? Because excellent writing for humans usually lacks the explicit structure models need.
I rebuilt a client’s resource center last month using structured templates. Same topics. Same expertise. Different architecture. Within three weeks, their content appeared in AI-generated responses 400% more frequently. Traffic from AI-powered search tools increased by 180%.
The work wasn’t glamorous. We didn’t rewrite everything. We restructured. Added entity markup. Built FAQ blocks. Created semantic headers. Connected content through explicit relationship markers.
The investment paid off faster than traditional content marketing ever did.
Content Teams Still Optimize for Readers. AI Engines Optimize for Structure.
Leaders who see the gap now won’t just survive the next decade. They’ll shape it.
I’m still learning. I run new tests every month. The models evolve, my understanding deepens, and the patterns become clearer. But one thing I know for sure: the way we’ve been creating content for the past 20 years doesn’t match how AI systems extract meaning today.
The question isn’t whether to adapt. Whether you’ll be early or late matters more.
Every conversation I have with content leaders reveals the same tension. They know something fundamental has changed. They see competitors gaining ground. They watch their best content fail to appear in AI responses. But they don’t know where to start.
Start with structure. Start small. Take one high-value page and rebuild it with entity markup, FAQ blocks, and semantic headers. Test it across multiple AI models. Document what changes. Then scale what works.
The teams that move now will define content authority for the next decade. The teams who wait will spend years catching up to a game that early movers are already playing at a level they didn’t know existed.
I’ve placed my bet. I’m building for AI-native content systems while most teams are still optimizing for last decade’s search algorithms. The gap between these approaches isn’t closing. It’s accelerating.
Frequently Asked Questions About AI Native Content Systems
How do AI models read long-form content?
AI models read content through attention patterns and embeddings. They reorganize meaning based on token relationships, entity signals, and structural clarity. They do not follow human formatting or narrative order.
Why does structured content perform better in generative search?
Structured content gives models clear signals. Entity markup, semantic headers, and FAQ blocks create boundaries. These boundaries help retrieval systems extract intent, relationships, and meaning with higher accuracy.
Why does high-quality writing fail in AI-powered retrieval?
High-quality writing often hides key signals inside long paragraphs. AI models need explicit structure, not elegance. Without clear entities and relationships, the model guesses which parts matter.
What is an AI native content system?
An AI native content system starts with architecture before copy. It defines entities, relationships, schemas, and extractable sections. It treats each page as data, not prose.
How does entity markup improve visibility?
Entity markup defines meaning in a machine readable format. It helps models understand what a page covers, how concepts relate, and which sections matter. Structured entities increase extraction accuracy across models.
How do I know if my content is invisible to AI models?
Test your content across multiple models. Run summaries. Ask questions. Review what each model extracts. If the answers ignore your core message, your structure needs work.
What is extraction accuracy?
Extraction accuracy measures how often an AI model pulls the correct meaning, facts, or relationships from a page. Leaders track this metric to understand how models interpret their content.
What is the fastest way to make content more model friendly?
Start with one page. Add clear headers. Add a summary block. Add FAQ sections. Add explicit entities. Connect the page to related content. Test again across multiple models.
How will this shift impact content teams in 2026?
Teams that rely on narrative quality will lose visibility. Teams that publish structured, machine readable pages will gain visibility in generative search. Structure becomes the new authority signal.
Why does this matter for leaders?
Leaders who treat content as data shape AI-generated responses. Leaders who ignore structure fall behind as models route users to content they can extract from.
I’m always experimenting with new approaches to AI-native content. If you’re seeing similar or different patterns, I’d genuinely like to hear about them. Moving fast defines the space, and the best insights come from people doing the work.
Stay Connected
I share new leadership frameworks and case studies every week. Subscribe to my newsletter below or follow me on LinkedIn and Substack to stay ahead and put structured decision-making into practice.
Related Articles
The Truth About Enterprise SEO and Why It Fails
The Truth About AI-Driven SEO Most Pros Miss
Intent-Driven SEO: The Future of Scalable Growth
SEO Strategy for ROI: A Better Way to Win Big
Future of SEO: Unlocking AEO & GEO for Smarter Growth
Skyrocket Growth with Keyword Strategy for Founders
Unlock Massive Growth with This 4-Step SEO Funnel
AI Traffic in GA4: How to Separate Humans vs Bots
About the Author
I write about:
- AI + MarTech Automation
- AI Strategy
- COO Ops & Systems
- Growth Strategy (B2B & B2C)
- Infographic
- Leadership & Team Building
- My Case Studies
- Personal Journey
- Revenue Operations (RevOps)
- Sales Strategy
- SEO & Digital Marketing
- Strategic Thinking
📩 Want 1:1 strategic support?
🔗 Connect with me on LinkedIn
📬 Read my playbooks on Substack
Leave a Reply