The Layer That Makes AI Execution Reliable
Most operators deploying AI hit the same wall. The tools work. The prompts improve. Outputs look reasonable in testing. Then production arrives and everything becomes inconsistent. The same input produces three different outputs. Human review increases. Execution slows down instead of speeding up.
The instinct is to fix the prompts. That is the wrong diagnosis.
The problem is not the model. It is not the prompt. It is the absence of a decision infrastructure layer. This is the architectural component that governs how AI systems evaluate context, route execution, validate outputs, and compound intelligence across workflows. Without it, AI tools operate as isolated responders rather than as a governed system.
This article defines decision infrastructure, explains why its absence is the root cause of most AI execution failures, and introduces the Decision Infrastructure Stack. That is a five-layer model for building reliable AI execution inside real operator workflows.
| What is decision infrastructure? Decision infrastructure is the layered system that converts signals into reliable AI execution decisions. It sits between raw input and final output, governing how context gets assembled, how execution paths get selected, how outputs get validated, and how each decision improves the next. Its absence is why AI deployments produce inconsistent results even when individual tools function correctly. |
What Is Decision Infrastructure?
Decision infrastructure sits between raw input and final output. It governs how context gets assembled, how execution paths get selected, how outputs get validated, and how each decision improves the next one. Not a single tool. Not a prompt template. An architectural property of the entire workflow.
Most operators build AI workflows without this layer. They connect tools directly to triggers, route outputs through static logic, and rely on the model to handle ambiguity. That approach works in demos. It degrades under real conditions.
Decision infrastructure changes the architecture. Instead of asking what this model should output, the question becomes: what is the governed path through which this input becomes a reliable execution decision? That shift in framing separates AI deployments that scale from ones that plateau at pilot.
What People Get Wrong About AI Execution Failures
The most common misread is that AI execution failures are model failures.
They are not. The model is usually doing exactly what it was asked to do. The failure is structural. The workflow asked the model to resolve ambiguity that the infrastructure should have resolved first. The workflow sent incomplete context and expected complete output. The workflow routed output downstream without validating it against the decision boundary it was supposed to satisfy.
McKinsey’s 2025 State of AI report surfaces this pattern directly. Eighty-eight percent of organizations use AI in at least one function. Only approximately one-third report scaling AI across the enterprise. That gap is not a model capability gap. It is an infrastructure maturity gap. Understanding AI execution ROI starts with diagnosing which layer is missing, not which model is underperforming.
The organizations stuck at pilot stage are not using inferior models. They are running capable models on workflows that lack the structural layer required to make outputs reliable and repeatable at scale.
A second common misread is that better prompts solve the problem. Prompts improve output quality within a single call. They do not govern execution routing across a workflow. They do not validate that output satisfies a decision requirement before it moves downstream. They do not accumulate intelligence across interactions. Prompt engineering is a component. Decision infrastructure is the architecture that prompt engineering operates inside.
| Why do AI workflows fail even when the tools work correctly? Most AI execution failures are not model failures. They are infrastructure failures. The workflow asked the model to resolve ambiguity that a governed evaluation and routing layer should have resolved first. Adding better prompts to a workflow without decision infrastructure is like improving the engine on a car with no steering system. |
What Breaks Without This Layer
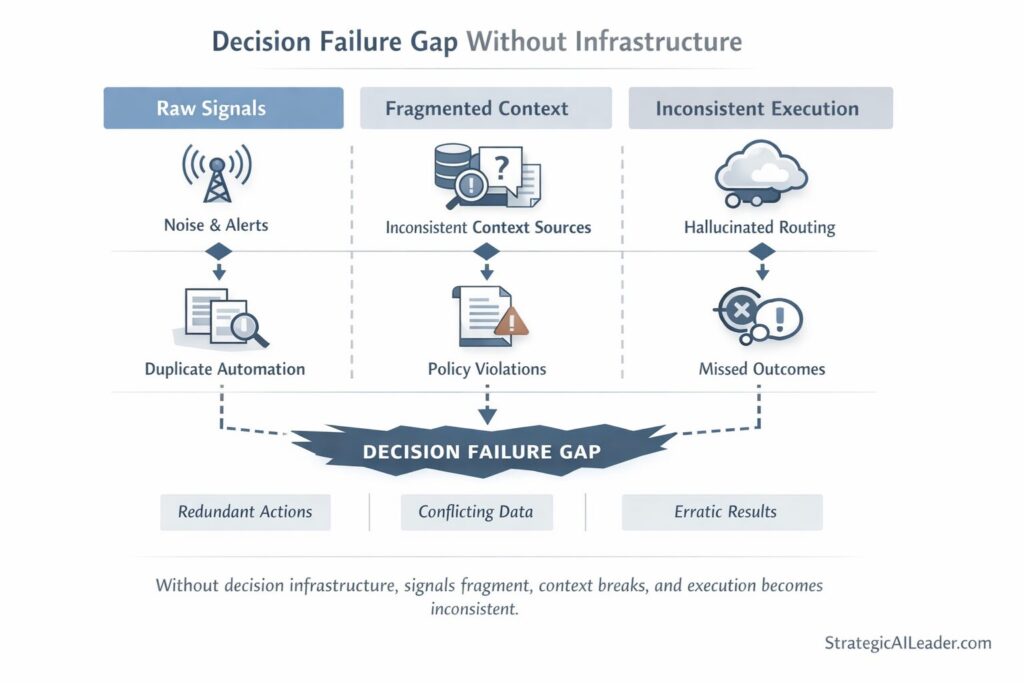
Signal fragmentation. The AI system receives partial context because no layer is responsible for assembling a complete picture before execution begins. The model compensates by inferring. Inference varies. Outputs vary.
Routing by default. Without an explicit evaluation layer, execution follows the path of least resistance. Same tool, same format, same response pattern regardless of whether it fits the actual decision requirement. This is how decision loops stall under AI load. Routing by default looks fine in low-volume testing. It compounds errors at scale.
No output boundary. The workflow has no defined standard against which outputs are validated before moving downstream. Inconsistent outputs pass through unchallenged. Human review increases to catch what the system missed. That cost is invisible in early pilots and unsustainable in production.
No compounding. Each decision is independent. Nothing is traced. Nothing feeds back. The system makes the same mistakes repeatedly because there is no mechanism for decisions to improve future decisions.
In the MyEListing sales workflow before decision infrastructure was introduced, all four failure modes were present. Lead response time averaged forty-eight hours. CRM accuracy sat at 60%. Pipeline conversion from MQL to SQL ran at 12%. The tools existed. The team was capable. The missing piece was the structured evaluation and routing system that would have connected signals to reliable execution decisions.
After building decision infrastructure, lead response time dropped to four hours, CRM accuracy reached 95%, and pipeline conversion improved to 27%. The tools did not change. The infrastructure did.
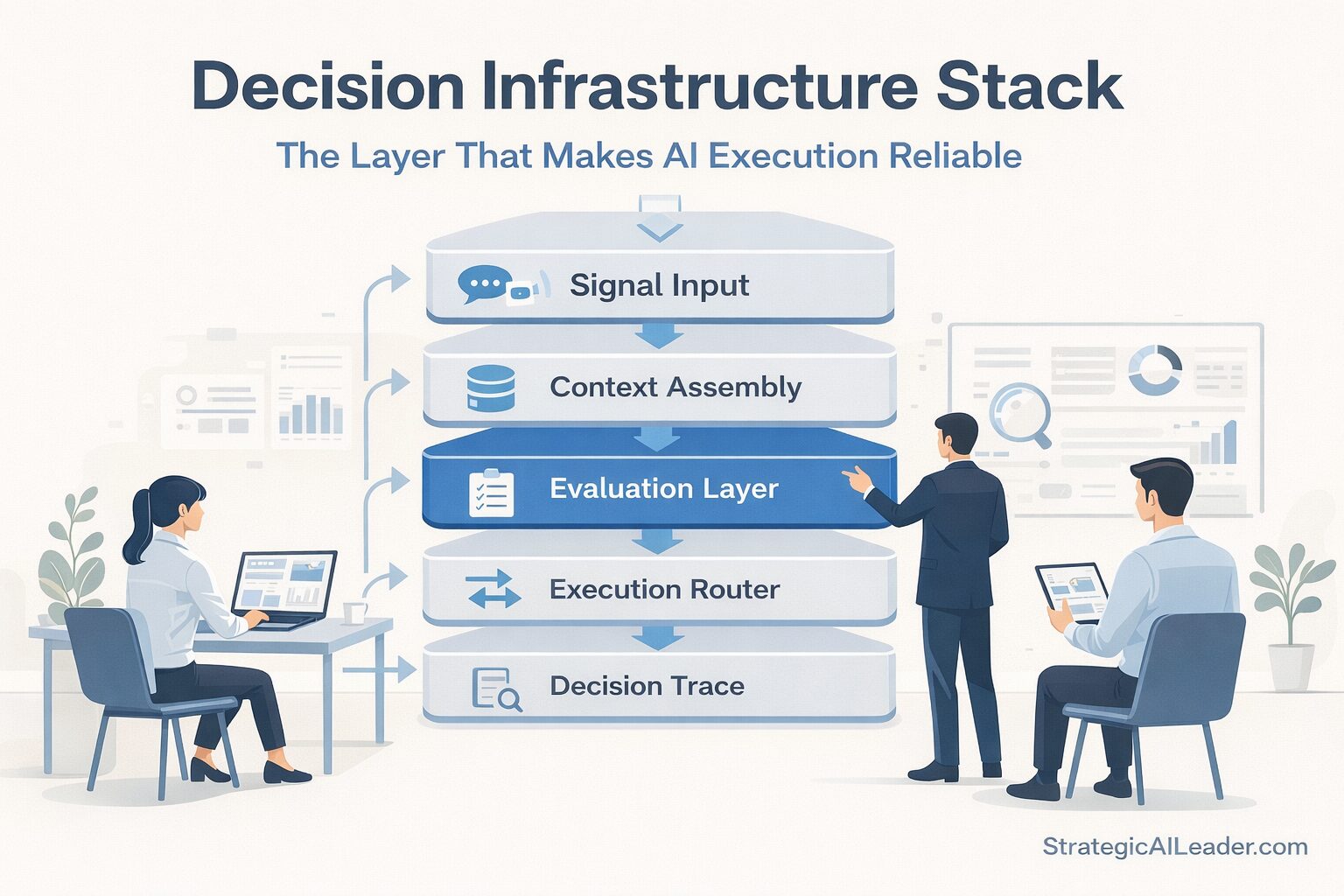
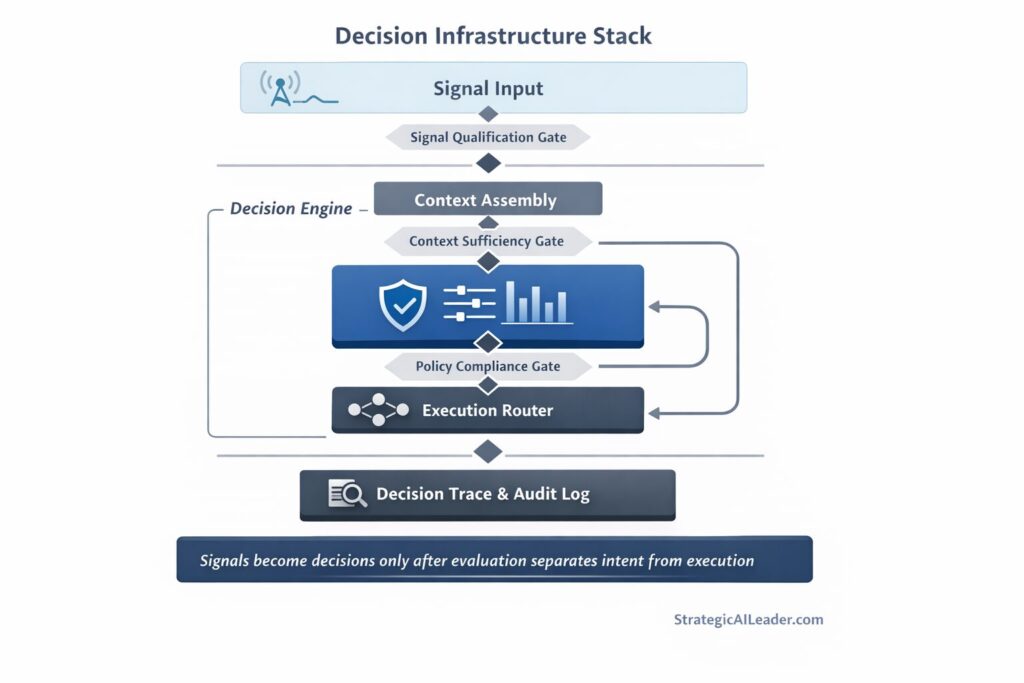
The Decision Infrastructure Stack
The Decision Infrastructure Stack is a five-layer model for building governed, traceable, reliable AI execution inside operator workflows.
Each layer has one job. Together they convert raw signals into execution decisions that are consistent, auditable, and capable of improving over time.
Layer 1: Signal Input
Every execution decision begins with what the system receives. User inputs, system state, contextual data, prior decisions, external triggers.
Most workflows treat signal input as a given. Decision infrastructure treats it as a governed collection problem. The question at this layer is not what the model should do with the input. The question is whether the complete signal set required to make a reliable decision has actually been assembled. Incomplete signal input is the most common source of execution variance. Fix it here rather than downstream.
Layer 2: Context Assembly
Context assembly converts raw signals into a structured representation of the decision environment. Relevant history gets retrieved. State gets attached. Decision type gets classified.
A well-assembled context block tells the model exactly what it needs to know and excludes everything that introduces noise.
McKinsey’s analysis of agentic enterprise architecture identifies the absence of a coordination fabric as the primary reason multi-agent deployments fragment. Context assembly is that coordination fabric at the single-decision level. Without it, each model call operates in partial isolation, and output quality depends entirely on what the model infers about context it was never given.
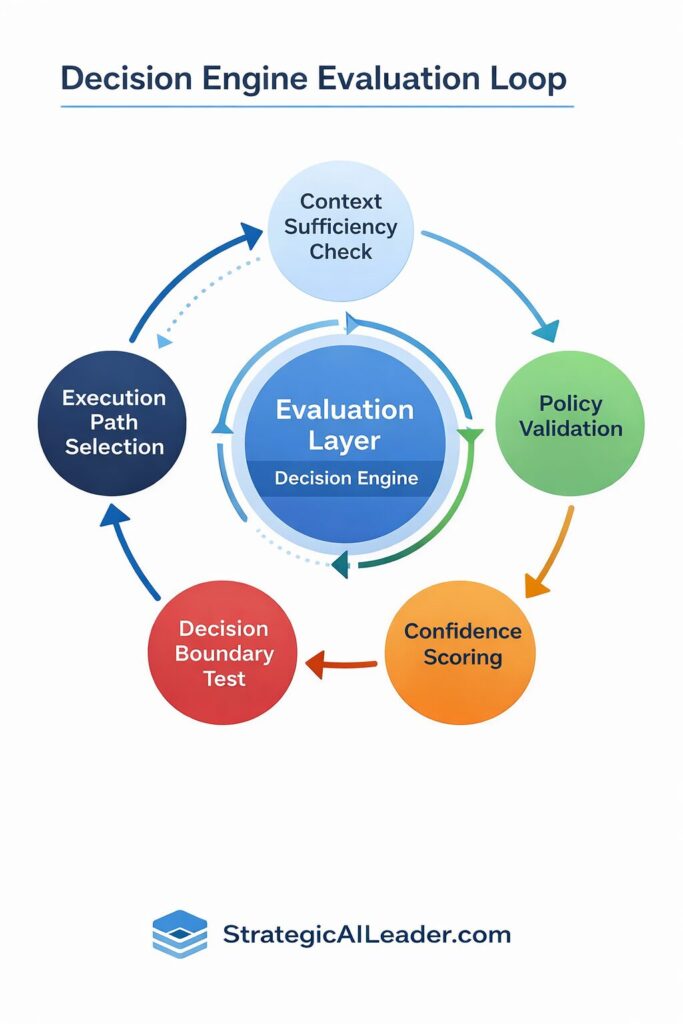
Layer 3: Evaluation Layer
The evaluation layer is the governed checkpoint between context and execution. It determines whether the assembled context is sufficient to proceed, what execution path is appropriate, and what the output must satisfy to count as a valid decision.
Most operator workflows skip this layer entirely. Context goes straight to execution. The evaluation layer inserts a ruled checkpoint. Business rules apply. Decision boundaries get validated. Execution path gets selected based on structured logic rather than model inference.
Deloitte’s infrastructure research frames this precisely: existing enterprise architecture was designed before AI workloads existed. Retrofitting AI into pre-AI infrastructure creates execution misalignment because the original design had no evaluation checkpoint between input and execution. This is the same gap that makes AI governance so difficult to enforce without an underlying decision layer to govern against.
Layer 4: Execution Router
The execution router directs the assembled, evaluated context to the correct tool, agent, or process based on the evaluation layer output.
The key distinction from typical tool-calling implementations: routing decisions here are governed. They follow explicit logic. They are logged. They can be audited. The model does not choose the path. The router does, based on rules the evaluation layer produced.
Separating the router from the model is what makes execution reliable under variation. When the model chooses its own path, output consistency is a function of inference quality. When the router chooses the path, output consistency is a function of architecture quality. Architecture quality is controllable. Inference quality is not.
Layer 5: Decision Trace
The decision trace logs every execution decision with enough context to audit it, learn from it, and replay it.
Without a trace layer, the workflow produces outputs. With a trace layer, the workflow produces outputs and accumulates institutional intelligence. Each traced decision becomes a data point for improving evaluation logic, refining routing rules, and identifying where the system produces systematic variance.
McKinsey’s research on AI decision-making frameworks identifies decision traceability as a prerequisite for moving from task automation to decision design. Organizations that trace decisions improve their execution infrastructure over time. Organizations that do not are running the same workflow repeatedly with no mechanism for learning.
| What are the layers of the Decision Infrastructure Stack? The five layers are: 1) Signal Input (governed collection of complete context), 2) Context Assembly (structured representation of the decision environment), 3) Evaluation Layer (ruled checkpoint between context and execution), 4) Execution Router (governed path selection to the correct tool or process), and 5) Decision Trace (logged record that compounds intelligence across decisions). |
What the MyEListing Sales Audit Taught Me
I worked through this directly when auditing the MyEListing sales workflow.
My initial assumption was that the inconsistency problem was a data quality problem. CRM records were incomplete, lead data was fragmented, and handoffs between marketing and sales were manual. My first attempt focused on improving data hygiene and adding automation to the handoff process.
That helped at the margins. It did not fix the core problem.
The core problem was no evaluation layer governing what happened between signal arrival and execution decision. A lead entered the system. A response went out. Nothing governed which response type was appropriate, whether the context was complete enough to respond reliably, or what a valid response actually looked like for this decision type. The model was resolving all of that by inference on every call.
I rebuilt the workflow with the Decision Infrastructure Stack as the organizing model. Signal input became a governed collection step with defined required fields. No downstream execution until the signal set was complete. Context assembly attached CRM history, prior interaction data, and deal stage classification before anything reached the evaluation layer. The evaluation layer applied routing logic based on lead type and stage rather than leaving that inference to the model. The router sent each lead to the correct response path. The trace logged every decision.
The results were not immediate. The first version had gaps in the context assembly layer. It was pulling history from the wrong CRM fields. I caught that in the trace logs, adjusted the assembly logic, and ran the workflow again. The second version stabilized.
Lead response time dropped from forty-eight hours to four. CRM accuracy went from 60% to 95%. Pipeline conversion from MQL to SQL improved from 12% to 27%. Deal throughput per rep increased 20%.
The improvement was not from better prompting. It came from replacing a workflow that asked the model to resolve ambiguity with a workflow that resolved ambiguity before the model was involved.
How to Know If You Have a Decision Infrastructure Gap
Five signals that this layer is missing:
Same input, different output. If the same type of input produces meaningfully different outputs across sessions, the evaluation layer is absent or underdefined. The model is resolving ambiguity differently each time rather than following governed routing logic.
Increasing human review. If review volume grows as AI output volume grows, the system has no output validation layer. Every output requires a human check because the infrastructure cannot determine what a valid output looks like.
AI slowing decisions. If AI-assisted workflows take longer than manual workflows, execution routing is broken. The system is adding steps without governing them.
No trace of why decisions were made. If you cannot explain why the workflow produced a specific output on a specific input, the trace layer is absent. Outputs exist without accountability.
Tools working but workflows not. If individual tools perform well in isolation but produce unreliable results in sequence, the routing and evaluation layers between them are missing.
Any three of these signals indicate a decision infrastructure gap. All five indicate a systemic architecture problem that prompting and tool selection cannot resolve.
| How do I know if my organization has a decision infrastructure gap? Look for these signals: same inputs producing different outputs, human review growing alongside AI output volume, AI workflows slower than manual alternatives, no ability to explain why a specific output was produced, and individual tools performing well but combined workflows producing unreliable results. Three or more of these present simultaneously indicate a decision infrastructure gap. |
Building Decision Infrastructure: Highest-Impact Starting Points
Define the decision boundary first. Before building any workflow, write down what a valid output looks like. What does this execution decision need to satisfy? What are the conditions under which the output is wrong? This defines evaluation layer criteria before a single tool is selected.
Separate context assembly from execution. Create an explicit step between input and model call that assembles the full context block. Do not pass raw input directly to the model. Assemble context first, validate completeness, then pass it forward.
Add one routing rule. Identify the highest-variance decision point in your current workflow. Write one explicit routing rule that replaces inference at that point with governed logic. Test the variance reduction.
Log every execution decision. Even a simple structured log of input type, routing path taken, output classification, and timestamp creates the foundation for a trace layer. Start logging before you need the data. The retrospective value is significant.
Audit one workflow with the Stack as a lens. Take your most inconsistent workflow and map it against the five layers. Identify which layers are absent. The gaps will be obvious. Fix the highest-impact gap first.
Operator Checklist
Before deploying or scaling any AI workflow, confirm:
- Signal input requirements are defined and enforced before execution begins
- Context assembly produces a complete, structured context block for every execution
- An evaluation layer governs execution path selection rather than leaving it to model inference
- The execution router follows explicit rules and logs its routing decisions
- A decision trace captures enough context to audit, learn from, and replay each decision
- Output validation criteria are defined before the workflow goes into production
- Human review triggers are explicit rather than applied to all outputs by default
If fewer than five of these conditions are true, the workflow has a decision infrastructure gap.
What This Changes About How You Build
Most operators approach AI workflow design as a tool selection problem. Pick the right model, write a good prompt, connect the output to the next step.
Decision infrastructure reframes the design process. The first question becomes: what is the governed path through which a signal becomes a reliable execution decision? Tool selection is downstream of that question, not upstream of it.
This reframe matters because it changes where debugging effort goes. A workflow with decision infrastructure fails in diagnosable, fixable ways. A workflow without it fails in ways that look like model problems but are actually architecture problems. No amount of prompt iteration resolves an architecture problem. The same logic applies to workflow compression: compressing human cognitive load with AI only works reliably when the execution layer beneath it is governed.
The organizations McKinsey identifies as AI high performers share one distinguishing characteristic: they treat AI as a catalyst for workflow redesign, not as a tool that improves existing workflows at the margin. Decision infrastructure is the architectural commitment that workflow redesign requires. Without it, AI remains a collection of useful tools that produce useful outputs in isolation and unreliable outputs in sequence.
Agent systems, multi-step automation pipelines, and any AI workflow operating in production at scale require this layer. Building it once, correctly, is faster than debugging inconsistency indefinitely.
Conclusion
AI execution failures are infrastructure failures.
The fix is not better prompting. Not a different model. Building the evaluation and routing layer that most workflows skip is the fix. That is the layer that governs how signals become execution decisions rather than leaving that governance to inference.
The Decision Infrastructure Stack gives operators a repeatable model for building that layer: governed signal input, structured context assembly, an explicit evaluation checkpoint, a ruled execution router, and a decision trace that compounds intelligence over time.
Build this layer before scaling your AI workflows. The MyEListing results, response time from forty-eight hours to four, CRM accuracy from 60% to 95%, pipeline conversion from 12% to 27%, did not come from better tools. They came from a governed architecture connecting those tools to reliable decisions.
The operators who scale AI successfully are not the ones with the best models. They are the ones who built the infrastructure layer that makes models reliable.
Help Support My Writing
Subscribe for weekly articles on leadership, growth, SEO and AI-driven strategy. You’ll receive practical frameworks and clear takeaways that you can apply immediately. Connect with me on LinkedIn or Substack for conversations, resources, and real-world examples that help.
Related Articles
The Truth About AI-Driven SEO Most Pros Miss
Intent-Driven SEO: The Future of Scalable Growth
SEO Strategy for ROI: A Better Way to Win Big
Future of SEO: Unlocking AEO & GEO for Smarter Growth
Skyrocket Growth with Keyword Strategy for Founders
Unlock Massive Growth with This 4-Step SEO Funnel
AI Traffic in GA4: How to Separate Humans vs Bots
About the Author
I’m Richard Naimy, an operator and product leader with over 20 years of experience growing platforms like Realtor.com and MyEListing.com. I work with founders and operating teams to solve complex problems at the intersection of product, marketing, AI, systems, and scale. I write to share real-world lessons from inside fast-moving organizations, offering practical strategies that help ambitious leaders build smarter and lead with confidence.
I write about:
- AI + MarTech Automation
- AI Strategy
- COO Ops & Systems
- Growth Strategy (B2B & B2C)
- Infographic
- Leadership & Team Building
- My Case Studies
- Personal Journey
- Revenue Operations (RevOps)
- Sales Strategy
- SEO & Digital Marketing
- Strategic Thinking
Want 1:1 strategic support?
Connect with me on LinkedIn
Read my playbooks on Substack
Leave a Reply